The Agentic Transformation of Software Engineering
A Deep-Dive Analysis of Core Concepts, Best Practices, and Industry Impact

Introduction: From Automation to Autonomy
The software development industry is undergoing a paradigm shift, moving from an era of task automation to one of agentic autonomy. This transition is not merely an incremental improvement in developer tools but a fundamental change in the nature of software itself. Historically, software has been a passive tool, meticulously crafted with explicit procedural logic and wielded by human operators to perform predefined tasks.
The emerging paradigm of AI agents introduces software as an active, goal-driven collaborator—an entity that can perceive its environment, reason about complex objectives, and execute multi-step plans with minimal human intervention. This report provides an exhaustive analysis of the core concepts underpinning this transformation, tailored for professional engineers who will build, manage, and ultimately collaborate with these new digital counterparts.
A critical distinction, supported by recent academic reviews, must be made between "AI Agents" and the broader concept of "Agentic AI". An AI Agent is typically a modular, often single-entity system designed for specific, well-defined tasks such as filtering emails, querying a database, or coordinating a calendar. These agents enhance existing workflows through intelligent automation. Agentic AI, in contrast, represents a more advanced and systemic paradigm characterized by multi-agent collaboration, dynamic task decomposition, persistent memory, and orchestrated autonomy. For engineers, this distinction is paramount; it provides a necessary framework for scoping projects, managing complexity, and aligning the right computational architecture with the problem at hand. Deploying a single AI Agent is a tactical decision; building an Agentic AI system is a strategic one.
This report is structured to guide the professional engineer from the foundational components of a single agent to the complex dynamics of multi-agent ecosystems. Throughout this analysis, we will consistently frame our findings in terms of three orders of impact:
First-Order Impacts: Direct, immediate changes to an engineer's daily tasks and workflows. This includes using an agent to generate code, automate testing, or retrieve information.
Second-Order Impacts: Systemic changes to team structures, development methodologies, and software architecture. This encompasses the emergence of new engineering roles, the evolution of Agile and DevOps practices to accommodate AI teammates, and the design of new, agent-native system architectures.
Third-Order Impacts: Fundamental shifts in the software industry's business models, a wider labor market, and the strategic value of software itself. This includes the transition from Software-as-a-Service (SaaS) to Results-as-a-Service (RaaS) and the ethical and philosophical questions that arise from deploying autonomous systems at scale.
By deconstructing the core concepts presented in the guiding image, and integrating the critical challenges of context management, this report aims to equip engineers with the deep, nuanced understanding required to navigate and lead in the age of agentic AI.
Part I: The Anatomy of a Single Agent
This part deconstructs the essential components of an individual AI agent. It begins with the foundational loop of perception and action that connects the agent to its world, then moves inward to its cognitive and memory structures, and finally examines its capacity for executing complex plans and improving over time. Understanding this anatomy is the first step for any engineer tasked with building or integrating these systems.
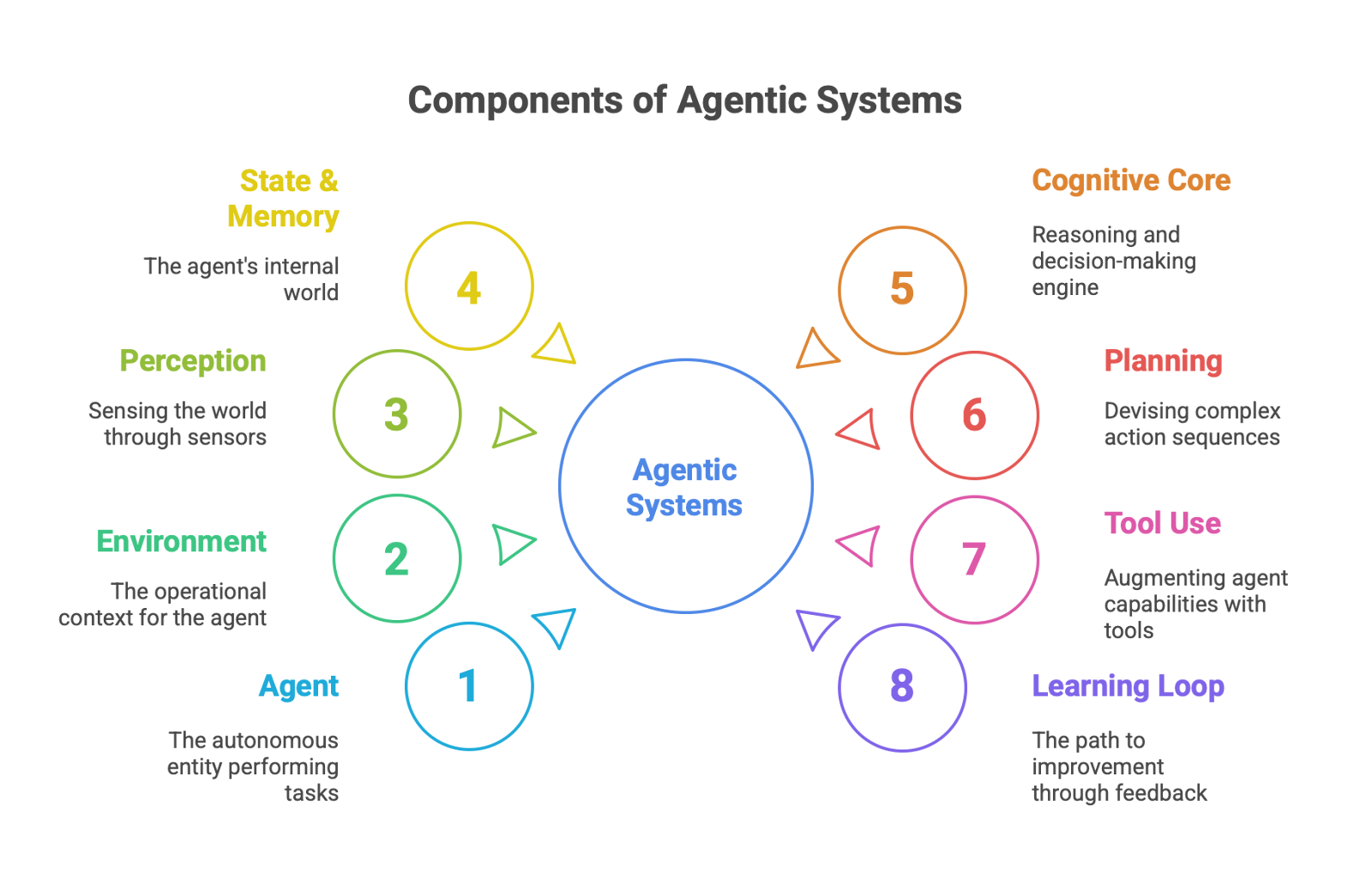
Section 1: The Agent-Environment Loop: Foundational Components
The classical model of artificial intelligence defines an agent through its interaction with an environment. The agent perceives the environment, processes that information, and takes actions that alter the environment, creating a continuous feedback loop. This section analyzes the four fundamental components of this loop, updated with the latest advancements driven by Large Language Models.
1.1. Agent: The Autonomous Entity
An Agent is an autonomous entity that perceives its environment through sensors, reasons about its perceptions, and acts upon that environment through actuators to achieve specific goals. The defining characteristics of a modern agent are its autonomy, task-specificity, and reactivity.
Autonomy implies the capacity to function with minimal or no human intervention after initialization, making agents suitable for applications where persistent oversight is impractical, such as in customer support or scheduling. Task-specificity means agents are typically purpose-built for narrow, well-defined domains like database querying or reconciling financial statements, which allows for high efficiency and precision. Finally, reactivity is the ability to respond to real-time stimuli, such as user requests or changes in a software environment.
The most significant recent development is the evolution of the agent's core. Pre-2022 agents were often constrained by rule-based systems, but the contemporary agent is architected with a Large Language Model (LLM) serving as its central "brain" or reasoning engine. This LLM-centric design provides a foundation for more sophisticated reasoning, planning, and adaptation, moving agents from simple scripted responders to proactive, goal-driven collaborators.
This evolution has profound first- and second-order impacts for engineers.
First-Order Impact: The fundamental task of building a system's logic changes. Instead of writing explicit procedural code for every possible behavior, engineers now guide an LLM's reasoning through prompts, fine-tuning, and the provision of external tools. The act of "programming" becomes a process of shaping and constraining the behavior of a powerful, pre-existing intelligence.
Second-Order Impact: This shift elevates the engineering focus from low-level implementation details to a higher level of abstraction termed "mechanism engineering". The primary work involves designing the ecosystem around the LLM core—crafting the prompts that define the agent's persona and goals, developing the tools it can use, and engineering the feedback loops through which it learns and corrects itself. This represents a new set of required skills and a new way of thinking about the software development process.
1.2. Environment: The Operational Context
The Environment is the surrounding context in which the agent operates, perceives, and acts. For software agents, this is typically a digital space, such as a codebase, a network of APIs, a customer relationship management (CRM) system, or the internet at large. For embodied agents, such as those in robotics, the environment is the physical world. The nature of the environment dictates the complexity of the challenges an agent will face.
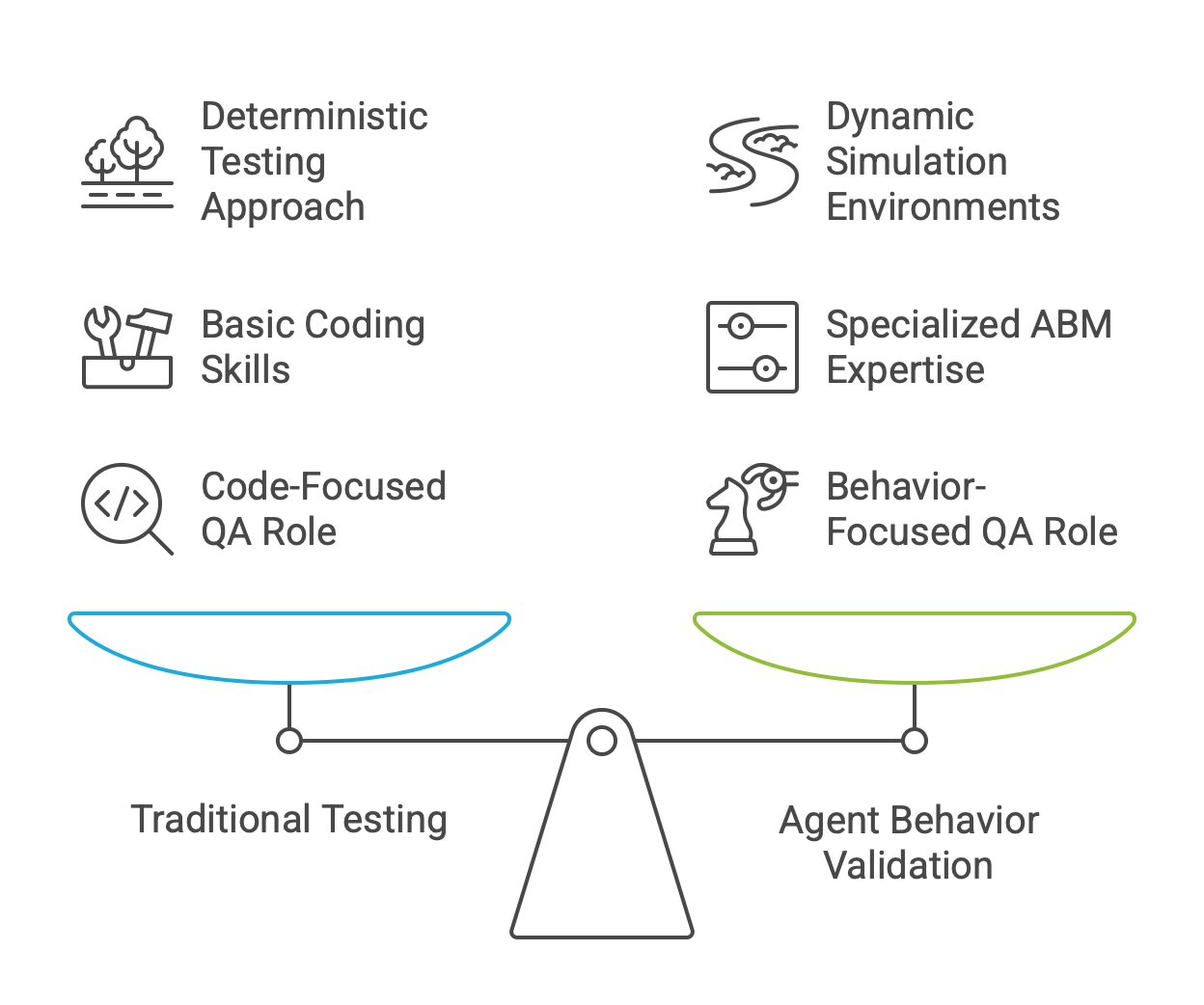
A critical challenge in agent development is bridging the gap between performance in controlled, static test environments and the messy, unpredictable reality of production environments. An agent that excels in a clean simulation may fail when confronted with the noisy, incomplete, and often adversarial data of the real world. Consequently, best practices in agent testing have evolved significantly. The focus is now on dynamic environment performance testing, a methodology that evaluates systems under conditions that mimic real-world unpredictability. This involves systematically introducing variability in inputs, simulating novel scenarios the agent has not been explicitly trained on, and progressively increasing the complexity of the tasks and interactions.
Simulation has emerged as an indispensable tool in this process. High-fidelity simulations allow developers to create virtual "digital twins" of production environments where agents can be tested against a vast range of scenarios, including rare but critical edge cases, without incurring real-world costs or risks. The sophistication of these simulations is advancing rapidly. For instance, researchers at Stanford have demonstrated the ability to create generative agent simulations of over 1,000 entities that replicate the complex social behaviors of real human populations, showcasing the potential to model highly complex interactive environments.
These developments have direct and transformative impacts on the engineering lifecycle.
First-Order Impact: The nature of software testing and Quality Assurance (QA) is fundamentally altered. Traditional unit and integration tests, which rely on deterministic inputs and predictable outputs, are insufficient for non-deterministic agents. Engineers must now design, build, and maintain dynamic simulation environments to validate agent behavior under a wide range of conditions. The task is no longer just to test code, but to test behavior in context.
Second-Order Impact: This shift necessitates new infrastructure, tooling, and skillsets. Teams will require expertise in agent-based modeling (ABM), simulation platforms, and techniques for creating realistic digital twins. The role of a QA engineer is likely to evolve into an "Agent Behavior Validation Specialist," whose job is to design challenging scenarios, analyze emergent behaviors, and certify that an agent is safe for deployment in its target environment.
1.3. Perception: Sensing the World
Perception is the process through which an agent acquires and interprets sensory or environmental data to build its internal representation of the world. It is the agent's primary input channel, the bridge between the external environment and its internal state.
The field of agent perception is rapidly advancing beyond simple text-based inputs. Modern agents are increasingly multimodal, capable of processing and integrating information from a diverse range of sources, including text, images, audio, and video. For physical agents, this sensory apparatus is even more complex, incorporating data from cameras, LiDAR, Inertial Measurement Units (IMUs), and various other IoT-enabled sensors to achieve situational awareness. A frontier in perception research involves using novel sensory modalities to infer user intent. For example, recent studies explore the use of eye-tracking (ET) data from wearable devices to provide an AI agent with a direct signal of the user's focus of attention in the physical world, enabling a far richer contextual understanding.
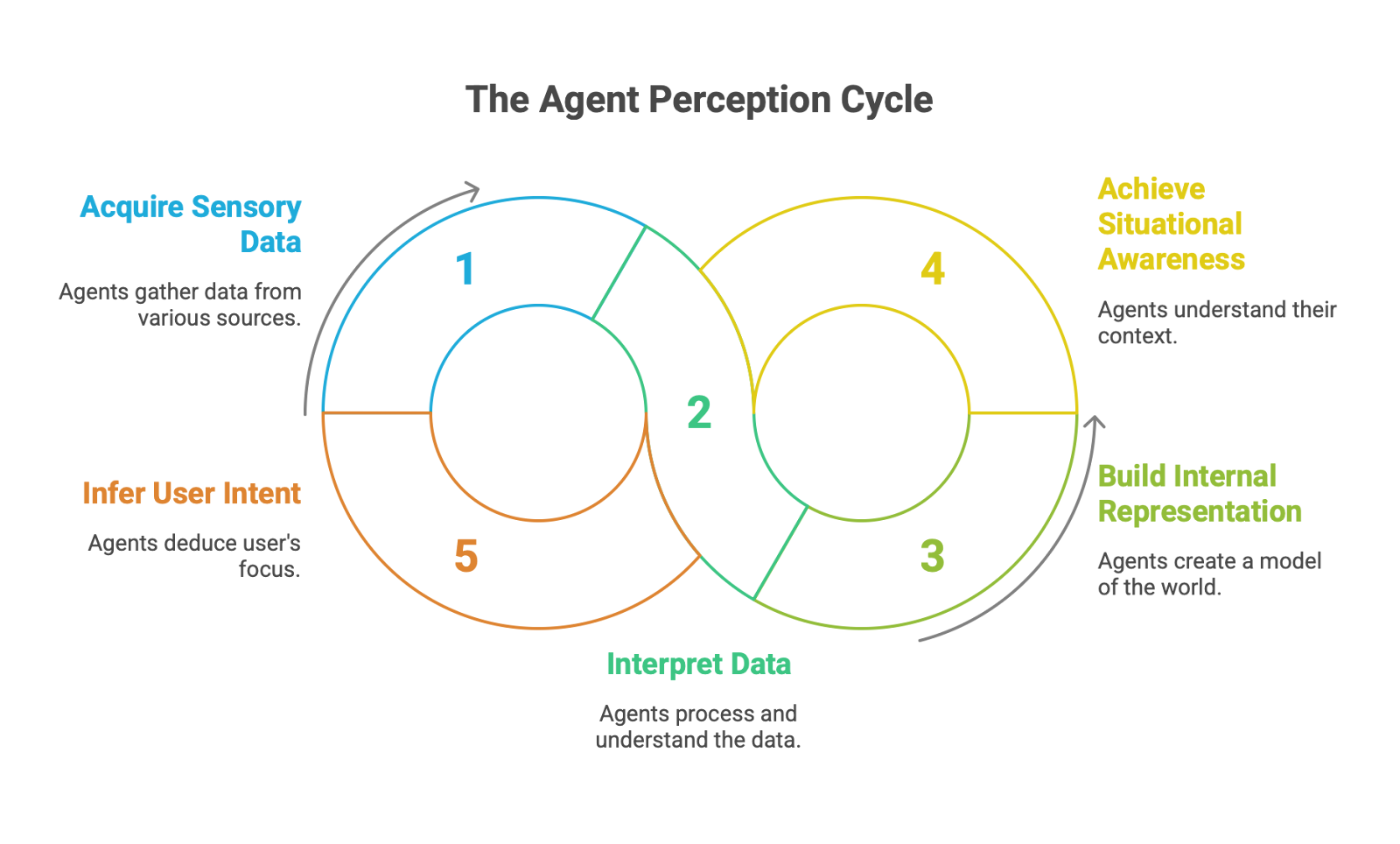
However, this expanded perceptual capability introduces new challenges. While agents can now "see" the world, their understanding of visual information can be brittle. Vision-Language Models (VLMs) can still misinterpret complex visual context or fail to grasp user intent from an image or video feed. Furthermore, perception can be skewed by inherent biases within the data representations themselves; for example, biased word embeddings can effectively blind an agent to certain concepts or lead it to make unfair associations.
The implications for engineers are significant and span multiple orders of impact.
First-Order Impact: The skillset required to build agents is broadening. Engineers must now be proficient in handling a variety of data types, including image and video streams, sensor data, and other unstructured formats. This involves new data ingestion pipelines, preprocessing techniques, and an understanding of the specific failure modes associated with each modality.
Second-Order Impact: The introduction of multimodal perception creates new categories of bugs and system failures. An agent that fails because it misinterpreted a visual cue in a user's environment represents a novel challenge that requires new debugging tools and methodologies. System architecture must account for these new, non-deterministic input streams and their potential for ambiguity or error.
Third-Order Impact: The drive for richer perception will accelerate the co-design of hardware and software. The development of consumer devices like smart glasses with integrated cameras, microphones, and eye-tracking sensors is inextricably linked to the development of AI agents that can leverage these data streams. This creates a new market for specialized, perception-tuned AI models and the hardware platforms that enable them.
1.4. State & Memory: The Agent's Internal World
State is the agent's current, internal representation of the world, including its understanding of the environment, the user's goal, and its own progress. Memory is the mechanism for storing and retrieving historical information, providing the continuity necessary for learning, adaptation, and coherent, multi-turn interactions. Together, state and memory form the agent's internal world model.
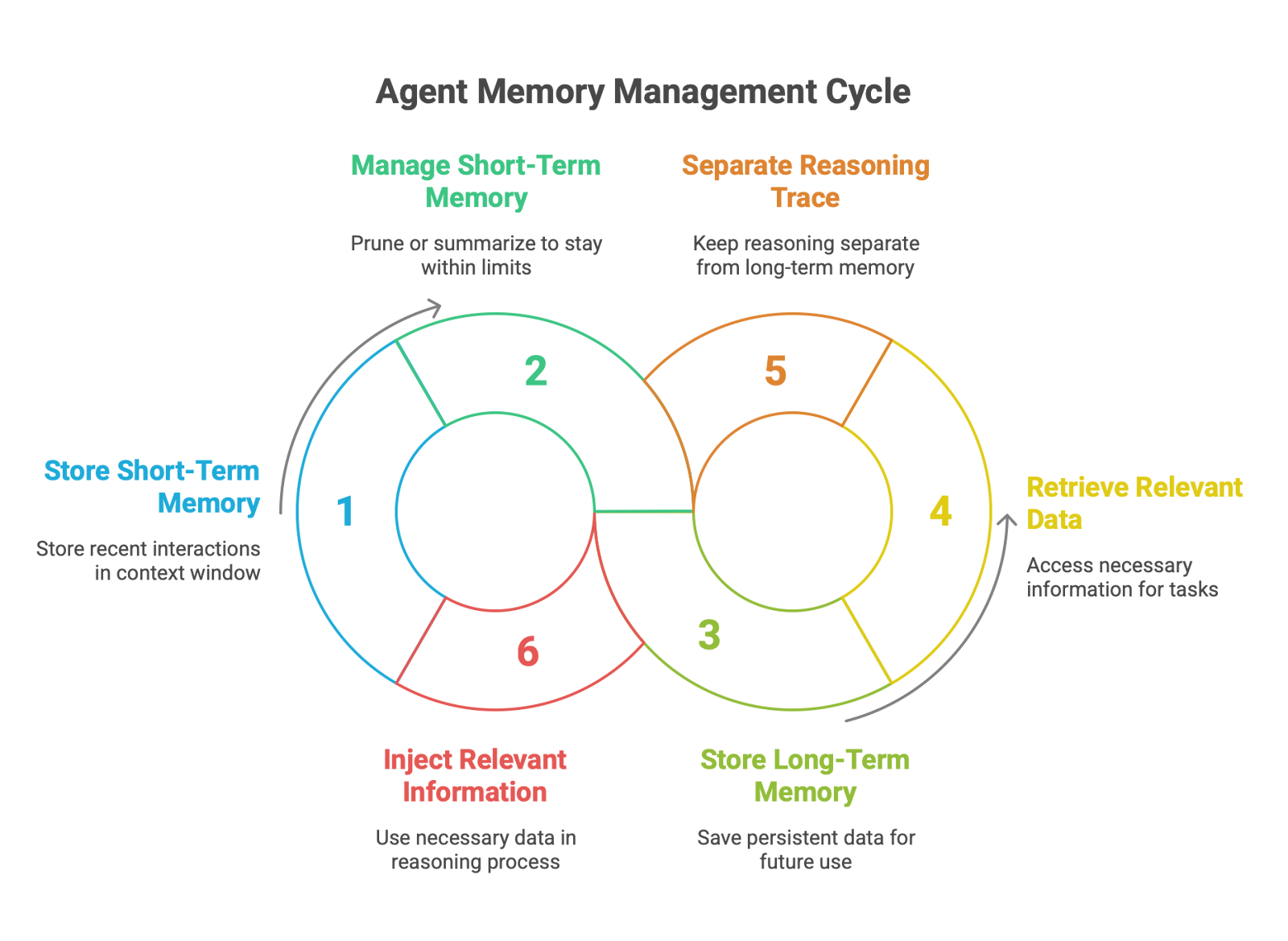
This area is one of the most critical and rapidly evolving frontiers in agent architecture. The central technical challenge is overcoming the inherent limitation of LLMs: their finite context window. An LLM can only "remember" the information provided within its current prompt, making true long-term persistence difficult. To address this, developers are engineering sophisticated memory systems, which can be broadly categorized into two types:
Short-Term Memory: This is typically implemented using the LLM's context window itself. It holds the history of the current conversation or task. As the interaction grows, this memory must be actively managed. Best practices include techniques like pruning older messages or using a secondary LLM to summarize long histories to keep the context relevant and within token limits.
Long-Term Memory: This is where the most significant innovation is occurring. The goal is to create persistent agents that can recall information and learn across sessions, days, or even months. Early approaches relied on simple vector databases for retrieving relevant past interactions. However, the state-of-the-art is moving toward more structured and comprehensive solutions. Frameworks like CoALA propose modular memory architectures that distinguish between working memory, long-term declarative memory (facts), and episodic memory (past experiences). Other research, such as the MemGPT project and its successor Letta, conceptualizes this as an "LLM Operating System" (LLM OS) that manages memory as a hierarchy, deciding what information to page into the LLM's limited "in-context" memory from a larger "out-of-context" storage. A key architectural insight emerging from practice is the importance of separating the agent's "scratchpad" or reasoning trace from its long-term memory. Storing every tool call and observation directly in the message history leads to token bloat and high costs. A more efficient best practice, seen in frameworks like LangGraph, is to store tool results and other observations in a structured state object and only inject the most relevant pieces of information into the LLM's prompt when needed for the next reasoning step.
The development of robust memory architectures has profound implications for software engineering.
First-Order Impact: Designing an agent's memory system is now a core architectural task for engineers. This is no longer a simple matter of managing session state; it involves selecting, integrating, and optimizing a combination of technologies—such as vector stores, graph databases, and traditional SQL databases—to create a hybrid memory system that can effectively serve the agent's needs.
Second-Order Impact: The rise of persistent, stateful agents challenges the long-held architectural preference for stateless services. Agentic systems are inherently stateful. This requires new design patterns for deployment, data management, state synchronization, and scalability, especially in multi-agent systems where memory might need to be shared or kept consistent across multiple interacting agents.
Third-Order Impact: The successful implementation of long-term memory is a crucial step toward creating more general and continuously learning AI. An agent that can autonomously reflect on its past experiences, synthesize new skills, and permanently update its knowledge base blurs the line between a static piece of software and a dynamic, evolving entity. This represents a fundamental shift in what software can be and do.
1.5. The Context Window Bottleneck: A Core Architectural Challenge
While LLMs serve as powerful reasoning engines, their performance is fundamentally constrained by a critical architectural limitation: the finite context window. This window represents the amount of information (measured in tokens) that a model can process in a single inference pass. Everything the agent needs to "know" for its next step—the user's query, the conversation history, retrieved documents from a knowledge base, available tools, and the system prompt—must fit within this limited space. This creates a significant bottleneck, giving rise to what is known as the Context Window Architecture (CWA) problem.
The CWA problem manifests as a series of cascading challenges that engineers must systematically address:
Information Overload and the "Lost in the Middle" Effect: Models tend to lose track of details presented in the middle of a large context window. This can cause the agent to ignore critical instructions, leading to incorrect or incomplete responses.
Latency and Cost Escalation: Larger context windows are not a panacea. Every token added to the prompt increases the computational load, leading to higher inference latency and API costs. For real-time applications, this trade-off between context richness and performance is a primary design constraint.
Structured vs. Unstructured Data Dilemma: Agents must often reason over a mix of structured (e.g., JSON from an API call) and unstructured (e.g., free-text documents) data. Naively dumping both into the context window is inefficient and can confuse the model. Effective CWA requires sophisticated strategies for selectively including and formatting this diverse information - often to match a specific model’s behavioral profile.
To overcome these challenges, engineers are developing a new set of architectural patterns and best practices for intelligent context management. These can be conceptualized as a "Context Stuffing Pipeline":
Contextual Scoping: The first step is to aggressively filter what information is even considered for inclusion. This involves using techniques like semantic search (RAG) to retrieve only the most relevant documents, and implementing business logic to select only the necessary parts of a long conversation history.
Contextual Compression: Once relevant information is identified, it must be compressed. This can involve using a secondary, smaller LLM to summarize long documents or chat histories, or using data extraction techniques to convert verbose text into a more compact, structured format like JSON.
Contextual Formatting: The final step is to format the compressed information in a way that is optimized for the LLM. This includes using clear separators, XML tags, or JSON structures to delineate different types of information (e.g., <instructions>, <retrieved_documents>, <chat_history>) and strategically placing the most critical information at the beginning or end of the prompt to mitigate the "lost in the middle" effect.
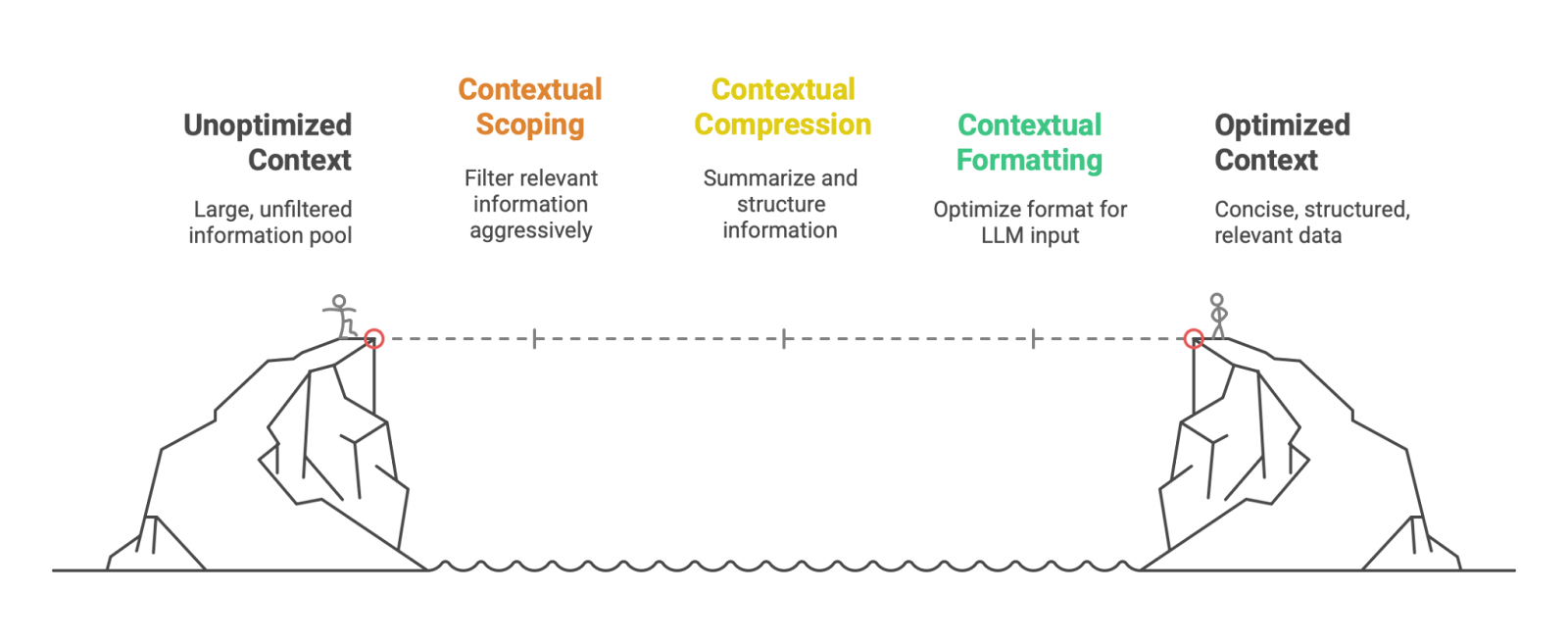
The CWA problem and the emerging solutions have direct and significant impacts on the engineering profession.
First-Order Impact: Context engineering is now a core competency for AI engineers. The task is no longer just about writing a good prompt, but about designing and building the entire data pipeline that populates that prompt. This requires a deep understanding of the trade-offs between context size, latency, cost, and model performance.
Second-Order Impact: The need for sophisticated context management is driving innovation in agent frameworks and tooling. We are seeing the emergence of more advanced state management objects (like in LangGraph) that separate transient "scratchpad" memory from the main context, and more intelligent RAG systems that can automatically handle the compression and formatting of retrieved data. This elevates the level of abstraction, allowing engineers to focus more on application logic and less on the mechanics of context stuffing.
Third-Order Impact: The CWA problem is a primary driver of research into new model architectures. The ultimate goal is to develop models with effectively infinite or highly efficient long-context capabilities that can natively handle vast amounts of information without performance degradation. Overcoming this bottleneck is a key step on the path toward more capable and general AI systems.
Section 2: The Cognitive Core: Reasoning and Decision-Making
While the agent-environment loop describes how an agent interacts with the world, its cognitive core determines the quality of those interactions. This section delves into the "brain" of the agent, analyzing the LLM that powers its reasoning, the knowledge it draws upon, and the structured patterns it uses to think and make decisions.
2.1. Large Language Models (LLMs): The Core Reasoning Engine
At the heart of every modern AI agent lies a Large Language Model (LLM). LLMs serve as the foundational component, providing the core capabilities for natural language understanding, generation, and, most critically, reasoning. It is the integration of LLMs as the agent's "brain" that has enabled the paradigm shift from rigid, rule-based automation to flexible, proactive, and goal-driven collaboration.
The latest developments in LLMs for agentic use are not necessarily about building the largest possible model. Instead, the trend is toward using a portfolio of smaller, specialized, and highly efficient models tailored for specific tasks, a practice necessary to manage the significant cost and latency overhead of agentic systems. For real-time, embedded agentic workflows, such as those in service operations or IT alerting, sub-second response times are critical. This has driven demand for models like Mistral Small, Meta's Llama 3 8B, Google's Gemini Nano, and Anthropic's Claude Haiku, which are optimized for low-latency inference. For agents operating in regulated or knowledge-intensive domains like finance or healthcare, the ability to fine-tune models on proprietary data and control their behavior is paramount. This favors open-weight, fine-tunable models like Llama 3 and Mistral over more closed, API-based offerings.
However, engineers must approach the LLM's reasoning capabilities with a healthy dose of skepticism. A significant critique, articulated in the "stochastic parrot" framework, argues that LLMs do not "reason" or "understand" in a human-like, semantic sense. Instead, they are immensely powerful pattern-matching engines that arrange linguistic symbols based on probabilistic information about their co-occurrence in training data. Their apparent reasoning is an emergent property of being steered by linguistic constraints, not genuine comprehension. This fundamental limitation manifests in several well-documented failure modes:
Hallucination: The tendency to generate factually incorrect or nonsensical information with high confidence.
Prompt Dependence: Extreme sensitivity to the phrasing of the input prompt, where small changes can lead to wildly different and incorrect outputs.
Inconsistency: The non-deterministic nature of LLMs can lead to unreliable and inconsistent outputs, even for the same input.
The Reasoning-Action Dilemma: Research has highlighted a paradox where superior performance on abstract reasoning benchmarks does not always translate to effective action in real-world agentic tasks. Agents can become trapped in loops of "overthinking" or "analysis paralysis," or act illogically despite having access to correct information.
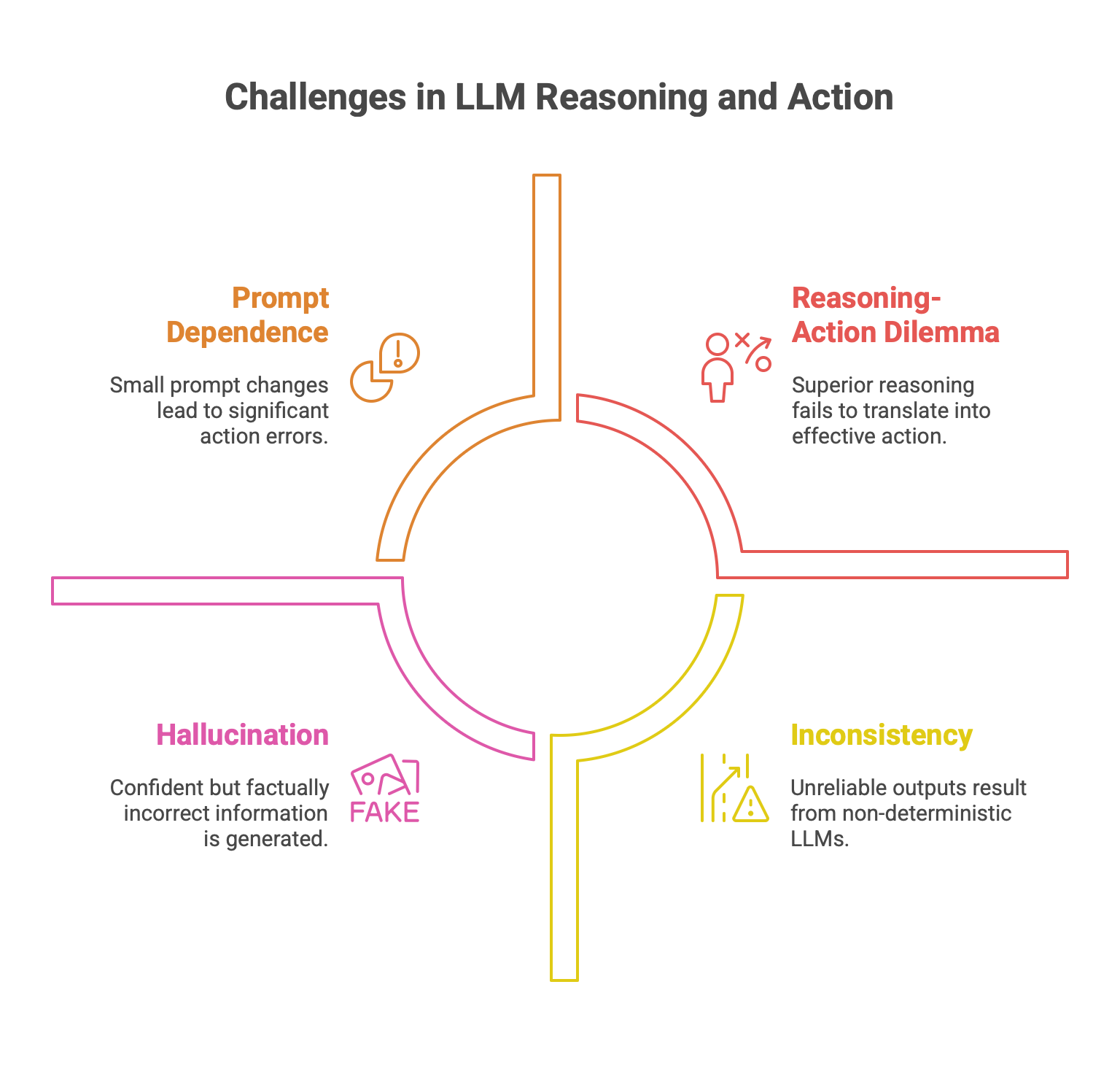
These limitations have direct and cascading impacts on the engineering process.
First-Order Impact: Engineers must treat the LLM as a powerful but inherently flawed component. The core engineering task becomes building robust systems around the LLM to mitigate its weaknesses. This includes meticulous prompt engineering, implementing validation layers to check the LLM's output, creating sophisticated error-handling routines, and fine-tuning the model to align its behavior with specific domain requirements.
Second-Order Impact: Architectural patterns must be designed to compensate for LLM deficiencies. A common and effective pattern is to use a "multi-model" strategy: a larger, more powerful (and expensive) model is used for complex, high-level planning, while smaller, faster (and cheaper) models are used for routine sub-tasks, with the entire workflow orchestrated within a multi-agent system. The entire testing paradigm for software must also be re-engineered to account for a core component that is non-deterministic by nature.
Third-Order Impact: The inherent limitations of "pure LLM reason" will be a primary driver of future AI innovation. This will spur the development of hybrid AI architectures that combine the strengths of LLMs (flexibility, natural language fluency) with the strengths of other AI paradigms, such as symbolic reasoning engines, formal methods for provable correctness , and structured knowledge bases, to create systems that are not only capable but also reliable and trustworthy.
2.2. Knowledge Base: Grounding Agents in Reality
A Knowledge Base (KB) is a structured repository of curated information that an agent uses to inform its decision-making process. Its primary purpose is to ground the agent's responses and actions in a source of factual, verifiable data, thereby reducing the risk of hallucination and ensuring the agent operates based on up-to-date, domain-specific information rather than relying solely on its static, parametric training data.
The predominant mechanism for interfacing an agent with a knowledge base is Retrieval-Augmented Generation (RAG). The RAG process can be understood through three key operations: TELL, which involves adding new facts or rules to the KB; ASK, where the agent queries the KB to retrieve relevant information to address a current scenario; and PERFORM, where the agent executes an action based on the inferred knowledge.
Modern knowledge-based agents often incorporate adaptive learning mechanisms, allowing them to update their rule sets over time based on recurring patterns or new information, blending structured knowledge with machine learning. This makes them particularly well-suited for compliance-heavy industries like finance and healthcare, where the traceability and explainability of a decision are crucial; every action can be traced back to a specific rule or fact in the KB.
Despite its power, the effectiveness of a knowledge base is entirely dependent on the quality of its underlying data. This introduces significant technical challenges for engineering teams. The most critical pitfall is insufficient data preparation. A knowledge base populated with poorly structured, incomplete, inconsistent, or biased data will inevitably lead to an ineffective and unreliable agent. Similarly, if the data is outdated, the agent's responses will be outdated, a critical failure for systems that must reflect current realities. Building the necessary data pipelines for collection, cleaning, document preparation, and preprocessing is a substantial engineering effort.
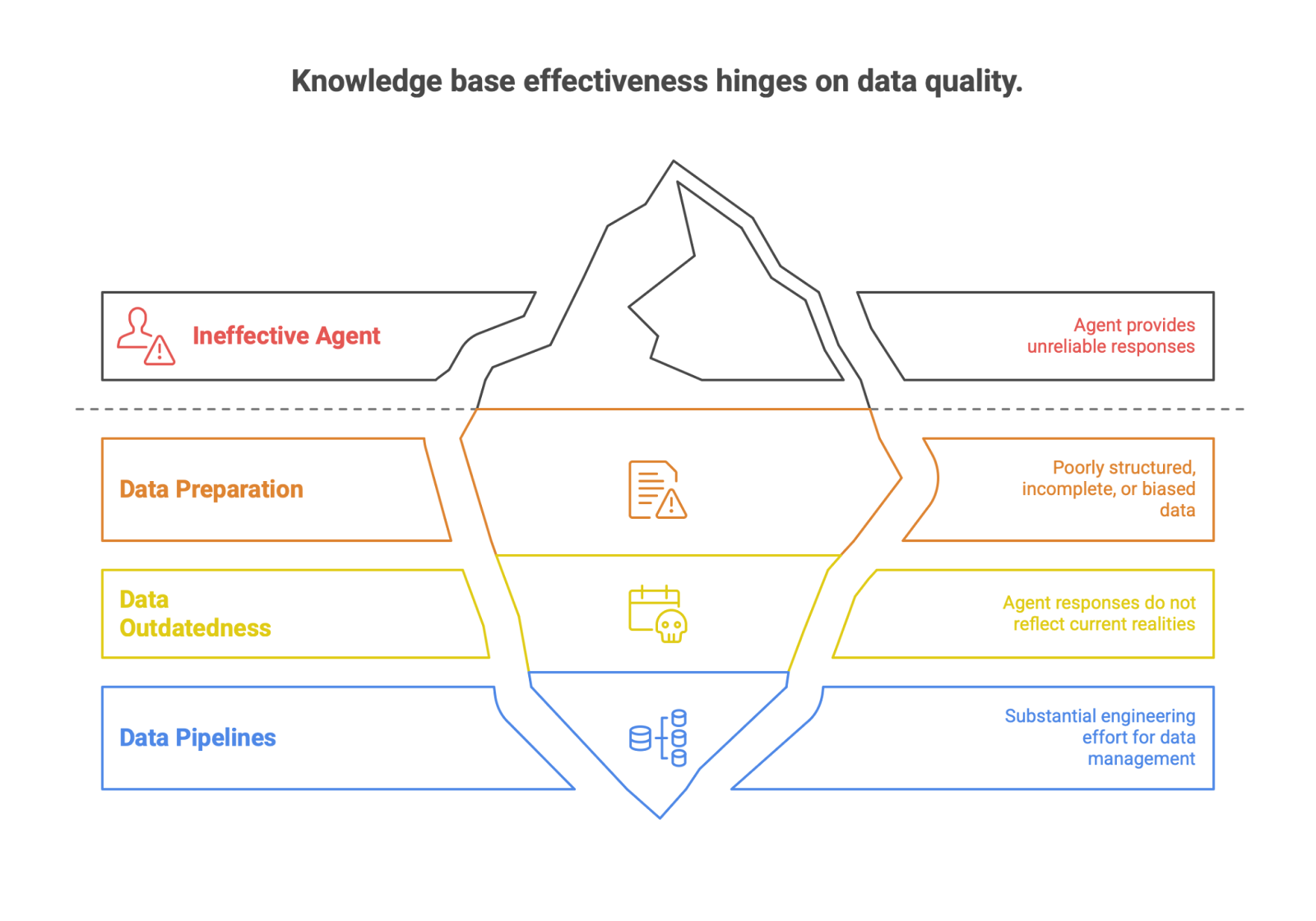
The central role of the knowledge base has cascading impacts on engineering practices and business strategy.
First-Order Impact: Building and maintaining a high-quality knowledge base is now a foundational activity in the development of many agentic applications. This is a significant data engineering task, requiring skills in ETL (Extract, Transform, Load) processes, data modeling, and the selection and management of appropriate storage technologies, most commonly vector databases for handling semantic search over unstructured text.
Second-Order Impact: The principle of "garbage in, garbage out" is amplified in the agentic context. An organization's ability to create and deploy effective agents is directly proportional to its data maturity. This elevates the importance of data governance and creates a need for new roles within technical teams, such as an "AI Knowledge Curator" or "Agent Librarian," who are responsible for the quality, accuracy, and maintenance of the agent's knowledge sources.
Third-Order Impact: In the long term, the quality and uniqueness of an organization's proprietary knowledge base will become a primary source of competitive advantage. Companies with well-structured, comprehensive, and clean internal data will be able to build custom agents that possess unique, high-value capabilities that cannot be easily replicated by competitors relying on public data or generic models. The knowledge base, therefore, transforms from a simple data store into a strategic corporate asset.
2.3. Reasoning Patterns: Structuring Thought
Agents employ different reasoning patterns, or cognitive strategies, to process information and decide on actions. The complexity of the pattern generally corresponds to the complexity of the task the agent is designed to handle. Engineers must select and implement the appropriate pattern for their use case.
2.3.1. Reflex Agent
The Reflex Agent is the most basic type of agent architecture. It operates on simple, predefined "condition-action" rules, often expressed as if-then statements. It perceives the current state of the environment and reacts immediately based on its rule set, without maintaining any memory of past states or considering future consequences. This makes its behavior analogous to a biological reflex.
Reflex agents are best suited for stable, predictable environments where quick, low-overhead, and deterministic responses are required. Common examples include thermostats that activate heating when the temperature drops below a threshold, automated email filters, vending machines that dispense an item upon receiving input, and simple robotic vacuums that change direction upon hitting an obstacle. In software engineering workflows, they can be used for simple automation tasks like scheduling meetings or sending templated emails.
The primary impact for engineers is that reflex agents provide a simple, reliable, and computationally inexpensive building block for basic automation. While they lack the sophistication for complex problem-solving, their simplicity and predictability make them a valuable tool for handling low-level, repetitive tasks within a larger, more complex software system.
2.3.2. Chain of Thought (CoT)
Chain of Thought (CoT) is a more advanced reasoning pattern where an agent explicitly generates a series of intermediate steps to solve a complex problem, rather than attempting to produce the final answer in a single pass. This technique is typically elicited from an LLM by either providing a few-shot prompt with examples that demonstrate step-by-step reasoning, or by using a simple zero-shot prompt like, "Let's think step by step". CoT has been shown to significantly improve LLM performance on tasks requiring logical, mathematical, or symbolic reasoning.
Recent research has yielded crucial insights into making CoT effective. One key finding is that the reasoning pattern of the examples provided in a few-shot prompt is more influential than the factual correctness of those examples. The model learns the structure of the reasoning process. Another advanced technique is Automatic Chain-of-Thought (Auto-CoT), which automates the selection of few-shot examples by first clustering a dataset of questions and then sampling a representative question from each cluster to generate a diverse and effective set of reasoning chain demonstrations.
CoT has significant impacts on engineering practices:
First-Order Impact: CoT is now a fundamental technique in the prompt engineering toolkit. To tackle complex problems, engineers must learn to structure prompts that encourage the LLM to "show its work." This act of externalizing the reasoning process improves the likelihood of arriving at a correct solution.
Second-Order Impact: The intermediate reasoning steps generated by CoT provide a crucial window into the agent's "thought process." This interpretability is invaluable for debugging and verification. When an agent fails, an engineer can inspect its reasoning chain to pinpoint the logical error or flawed assumption. This traceability is essential for building trust in non-deterministic systems and is a prerequisite for their use in any mission-critical application.
2.3.3. ReAct (Reason + Act) Framework
The ReAct (Reasoning and Acting) framework represents a major leap forward in agent architecture by synergizing the internal reasoning of CoT with the ability to interact with the external world through tools. The ReAct agent operates in an iterative loop:
Thought: The agent uses its reasoning capability to decompose the problem and formulate a plan.
Action: The agent decides to use an external tool (e.g., a search API, a calculator, a database query) to gather information or perform a computation.
Observation: The agent receives the output from the tool.
Repeat: The agent incorporates the new observation into its reasoning and decides on the next thought and action, continuing the loop until it has enough information to provide a final answer.
ReAct directly addresses the primary weaknesses of its predecessors. Unlike pure CoT, which can hallucinate facts because it lacks access to real-world information, ReAct can ground its reasoning in external knowledge. Unlike simple action-only agents, which can act but cannot plan, ReAct can formulate and adapt complex, multi-step strategies.
However, implementing ReAct in production reveals its own set of challenges. A common problem is token bloat, where the full history of thoughts, actions, and observations quickly consumes the LLM's context window, leading to high costs and latency. A second issue is lazy tool use, where the non-deterministic LLM may fail to use a necessary tool, or use it incorrectly. Best practices have emerged to mitigate these issues. For token bloat, engineers should manage the agent's state separately from the prompt history, only passing the most relevant observations back to the LLM for the next reasoning step. For lazy tool use, the solution is to implement deterministic control flow logic around the LLM, using the LLM to decide what to do but using code to enforce when and how tools are used, forcing the agent back to a reasoning step if it attempts to finish prematurely.
The ReAct framework is foundational to the current wave of agentic AI and has multi-layered impacts:
First-Order Impact: For engineers, ReAct is the go-to architecture for any agent that needs to perform tasks beyond simple text generation. Building a ReAct agent involves defining a set of available tools (APIs) and carefully engineering the main reasoning loop.
Second-Order Impact: The ReAct pattern enforces a highly modular and robust software architecture. It naturally separates the "thinking" component (the LLM) from the "doing" components (the tools). This separation of concerns makes the system easier to develop, test, and maintain. Individual tools can be updated or replaced without altering the core reasoning engine.
Third-Order Impact: ReAct is a cornerstone of the broader Agentic AI paradigm. It provides the fundamental mechanism for creating systems that can autonomously research, plan, and execute complex tasks that require interaction with the dynamic, information-rich external world. This capability is what allows agents to move out of the sandbox and begin performing meaningful work in business, science, and engineering.
Section 3: From Plan to Action: Execution and Evolution
An agent's cognitive core must be paired with the ability to execute its plans and, most importantly, to improve its performance over time. This section examines the agent's capacity for tool use, its methods for planning complex action sequences, and the learning loops that enable its evolution.
3.1. Tool Use: Augmenting Agent Capabilities
Tool Use refers to the agent's ability to leverage external systems, APIs, or other models to augment its own capabilities. Tools are the agent's "hands," allowing it to interact with and manipulate its environment, access information beyond its training data, and perform tasks that the core LLM cannot do alone, such as precise calculations or real-time data retrieval.
The frontier of tool use is pushing into highly specialized and scientific domains. While early examples focused on simple tools like web search or calculators, the latest developments involve giving agents access to a sophisticated toolkit of other models and scientific instruments. For example, the research lab FutureHouse has developed a suite of scientific agents, including PaperQA for advanced literature retrieval and synthesis, and Phoenix, an agent that can plan complex chemistry experiments by interfacing with specialized chemical modeling tools. This trend highlights a key principle: the power of an agent is increasingly defined not just by its internal reasoning ability, but by the quality and scope of the tools it can wield.
The centrality of tool use has significant impacts on the software engineering profession:
First-Order Impact: The concept of the "API economy" becomes even more critical in the agentic era. Engineers are no longer just building APIs for human developers or other services; they are now designing APIs to be used by autonomous agents. This requires a new focus on creating APIs that are not only well-documented and reliable but also "agent-friendly"—meaning they have clear, unambiguous specifications and provide responses that are easily parsable and understandable by an LLM. The agent itself becomes a primary user persona for the APIs an engineer builds.
Second-Order Impact: This paradigm naturally leads to the concept of Agent-as-a-Service (AaaS). Organizations will develop and offer highly specialized agents, packaged with their unique toolsets, as callable cloud services. Software architecture will evolve from being composed of microservices to being composed of interacting, specialized agents. A complex application might be built by orchestrating a "writing agent" from one vendor, a "data analysis agent" from another, and a custom-built "planning agent."
Third-Order Impact: The ability to creatively combine existing tools and invent new ones for agents to use will become a major driver of innovation. This will enable the automation of previously intractable, high-value workflows in fields like scientific research, drug discovery, and advanced engineering design, creating new markets and new avenues for discovery.
3.2. Planning: Devising Complex Action Sequences
Planning is the cognitive process by which an agent devises a sequence of actions to achieve a specific, often complex, goal. It is a higher-order capability that distinguishes sophisticated agents from simple reactive ones. The process begins with a clear goal definition and typically involves task decomposition, where the agent breaks the high-level objective down into a series of smaller, more manageable sub-goals.
Modern agentic planning is dynamic and feedback-driven. An agent doesn't just create a static plan and execute it blindly. Instead, it must be able to reflect on the outcomes of its intermediate actions and adapt its plan in response to new information, unexpected obstacles, or errors. The structure of these plans can range from a simple linear chain of tasks to more complex, non-linear structures like trees or graphs, which allow for branching logic and parallel execution. The growing importance of this capability is reflected in the emergence of dedicated benchmarks like PlanBench, MINT, and IBM's ACPBench, which are designed specifically to test the planning and reasoning prowess of advanced agents.
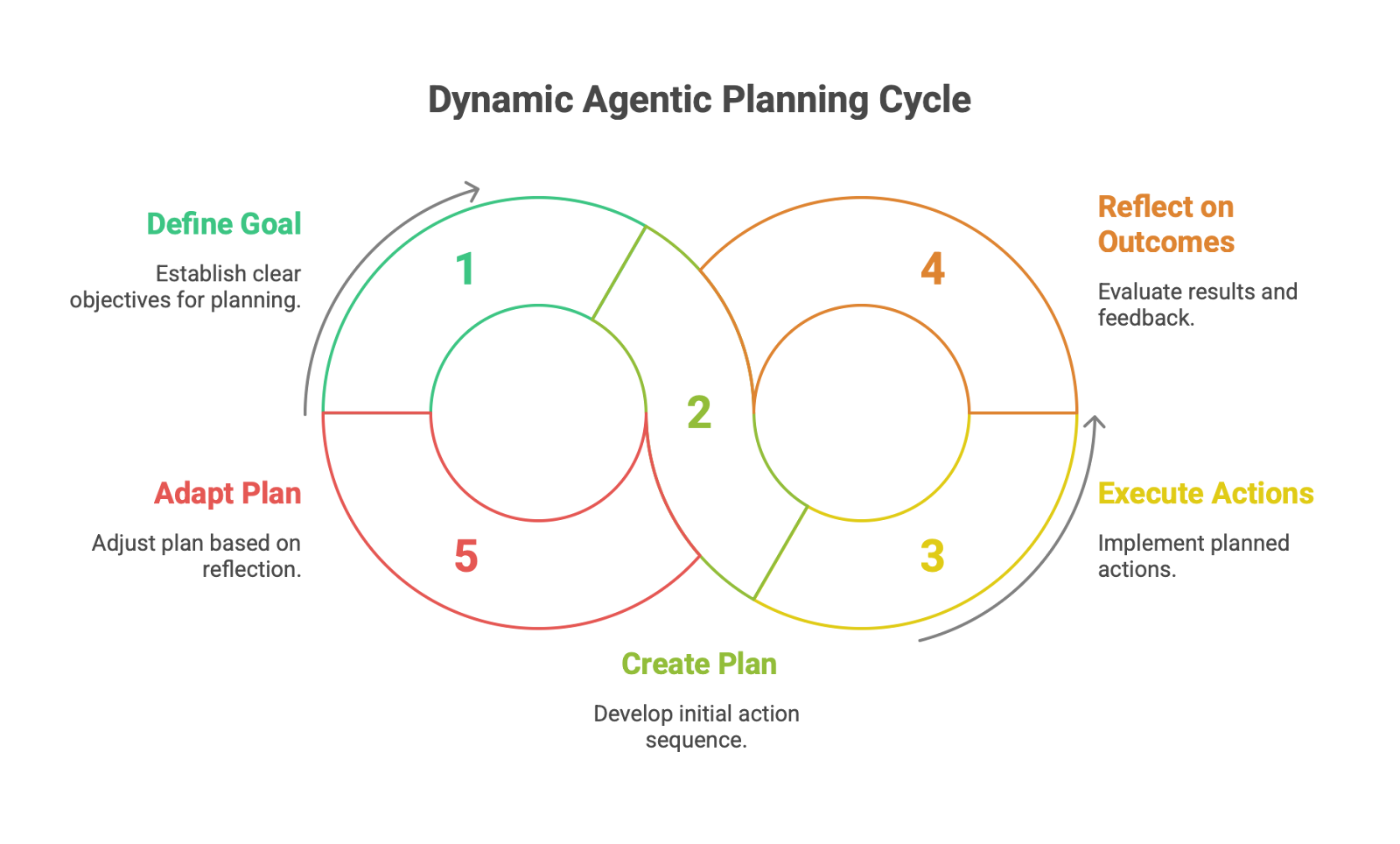
The rise of agentic planning fundamentally changes the role of the engineer:
First-Order Impact: Engineers are transitioning from being the authors of explicit plans (i.e., writing algorithms) to being the designers of "planners." The task is no longer to code the step-by-step logic for every scenario, but to create the prompts, systems, and feedback mechanisms that enable the agent to generate, execute, critique, and dynamically refine its own plans.
Second-Order Impact: This capability is set to transform workflow automation and project management. An AI project manager agent, for example, could take a high-level feature description (akin to a user story), decompose it into specific coding and testing tasks, assign those tasks to a "crew" of specialized developer and QA agents, and monitor their progress toward completion. This could fundamentally reshape Agile and DevOps methodologies, automating much of the coordination and execution overhead.
Third-Order Impact: As agentic planning capabilities mature, we will witness the emergence of increasingly autonomous systems capable of managing complex, long-term projects from inception to completion with only high-level human supervision. This shifts the human role away from tactical execution and toward strategic goal-setting, oversight, and exception handling, altering the very definition of management and leadership in technical domains.
3.3. Learning Loop: The Path to Improvement
The Learning Loop is the cyclical process that enables an agent to continuously improve its performance by learning from feedback and experience. This is the mechanism that transforms an agent from a static, pre-programmed tool into a dynamic system that can adapt and evolve. The canonical loop, often referred to as the perception-action-learning loop, consists of several stages: Observe (gather data from the environment), Decide (plan the next action), Act (execute the action), and Reflect (evaluate the outcome and update internal knowledge).
Two major paradigms dominate the implementation of learning loops in modern agents:
Reinforcement Learning (RL): RL provides a formal mathematical framework for learning from rewards and penalties. In the RL setup, an agent interacts with an environment, and for each action it takes, it receives a reward signal that indicates how "good" that action was in moving it closer to its goal. The agent's objective is to learn a policy—a strategy for choosing actions—that maximizes its cumulative reward over time. Deep Reinforcement Learning (DRL) combines RL with deep neural networks, allowing agents to learn complex behaviors in high-dimensional environments, such as playing video games from pixels or controlling robotic arms from camera inputs. The core of DRL is the continuous agent-environment interaction loop, where experience is used to update the agent's policy.
Human-in-the-Loop (HITL): For real-world deployment, relying solely on autonomous learning can be risky. HITL is a critical best practice that ensures safety and reliability by integrating human expertise and judgment at key decision points in the agent's workflow. HITL frameworks are designed to allow an agent to recognize when its confidence is low or when it encounters a novel or high-stakes situation, and to escalate the decision to a human operator. For instance, the HULA framework for software development allows human engineers to review, provide feedback on, and ultimately approve an agent's proposed plans and generated code before execution. This creates a collaborative learning loop, where the agent handles the bulk of the work but human oversight provides a crucial guardrail and a source of high-quality feedback.
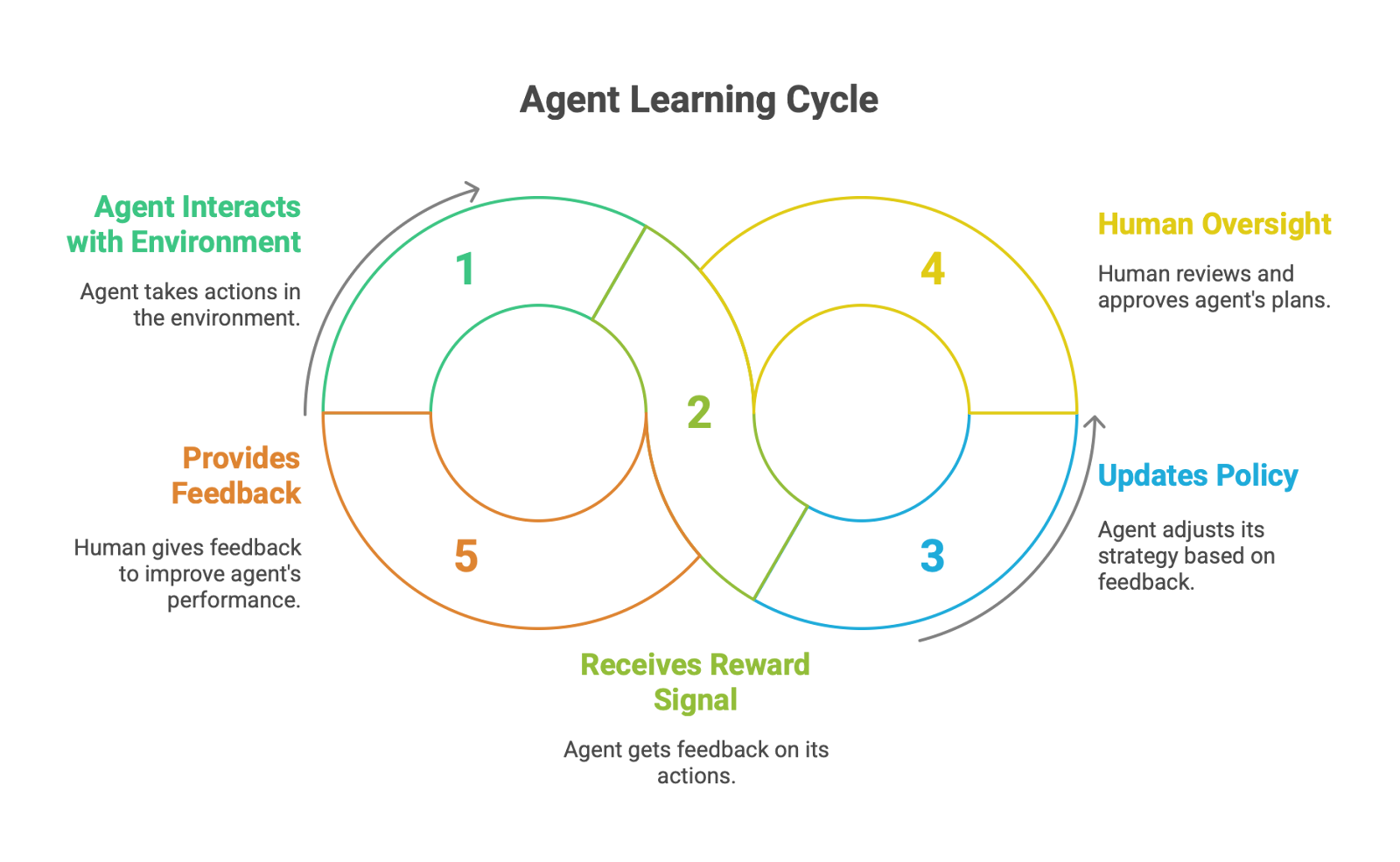
The implementation of learning loops has transformative effects on the software development lifecycle:
First-Order Impact: Building a learning agent requires engineers to explicitly design and implement feedback mechanisms. This can range from collecting implicit signals like user satisfaction scores or task success rates, to building explicit HITL approval workflows and user interfaces for providing corrective feedback.
Second-Order Impact: The development process itself becomes a continuous loop. The traditional model of "design, build, ship" is replaced by a model of "deploy, monitor, learn, evolve." Software teams must build and maintain robust MLOps (or, more accurately, AgentOps) pipelines that facilitate this cycle of continuous monitoring, evaluation, data collection, and retraining of agents in production.
Third-Order Impact: The learning loop is the engine that could potentially drive AI from narrow, task-specific intelligence toward more general and adaptable intelligence. An agent that can autonomously reflect on its own performance, identify its own weaknesses, and learn new skills from experience represents a fundamental departure from conventional software. The perfection of this loop is one of the grand challenges on the path toward Artificial General Intelligence (AGI).
Part II: The Ecosystem of Multiple Agents
Having dissected the single agent, the analysis now scales up to examine the dynamics of systems composed of multiple interacting agents. This is the domain of "Agentic AI," where complex, system-level behaviors emerge from the collaboration, coordination, and competition of individual autonomous entities. This shift from a single actor to a society of actors introduces new levels of capability, complexity, and risk.
Section 4: Multi-Agent Systems (MAS): The Collaborative Paradigm
The limitations of a single agent, no matter how powerful, become apparent when faced with complex, multifaceted problems. Multi-Agent Systems (MAS) address this by creating a framework where multiple, often specialized, agents can collaborate to achieve goals that would be beyond the reach of any individual agent. This collaborative approach is a defining feature of the Agentic AI paradigm.
4.1. Multi-Agent System: Definition and Architecture
A Multi-Agent System (MAS) is a computational system composed of multiple autonomous agents that interact within a shared environment. These agents collaborate, coordinate, and negotiate with one another to solve problems or perform tasks collectively. The core premise is the division of labor: complex problems are broken down, and specialized agents handle the sub-tasks for which they are best suited, emulating the principles of teamwork and specialization found in human societies.
The fundamental components of a MAS include:
Agents: The individual actors, each with defined roles, capabilities, knowledge, and behaviors.
Environment: The shared context, physical or digital, in which the agents are situated and can perceive and act.
Interactions: The communication and coordination mechanisms between agents, which can range from cooperation and negotiation to competition.
Organization: The structure that governs the relationships between agents.
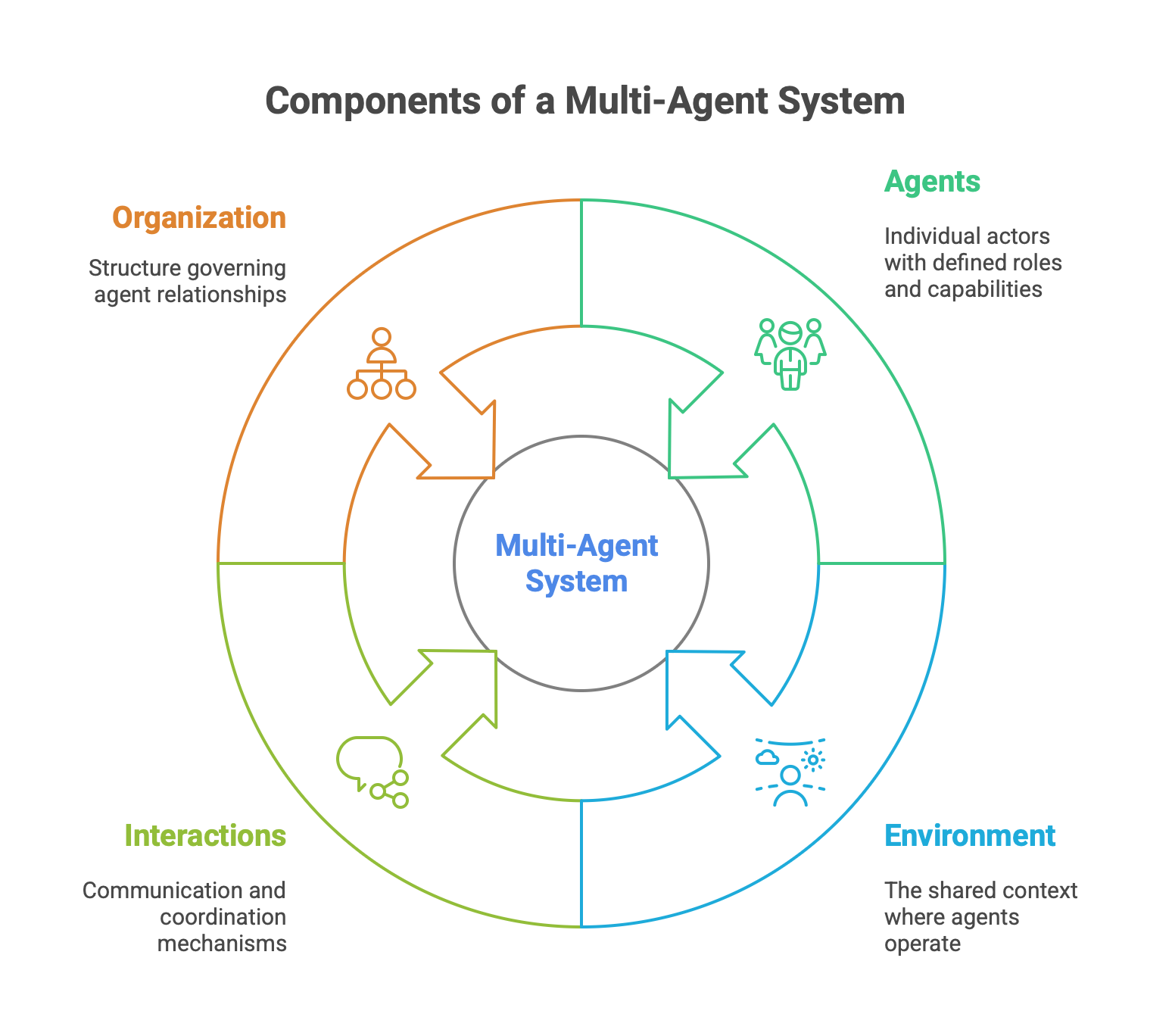
Two primary architectural patterns for MAS organization have emerged:
Centralized Architecture: This employs a hierarchical structure where a central "manager," "controller," or "orchestrator" agent is responsible for high-level planning. This controller decomposes the main goal into sub-tasks and allocates them to specialized "worker" agents. It then integrates the results to produce the final output. This top-down approach offers strong control and predictability.
Decentralized Architecture: In this model, agents interact directly as peers without a central authority. Coordination and global behavior emerge from local interactions and self-organizing protocols. This bottom-up approach provides greater robustness (no single point of failure), scalability, and flexibility, as the system can adapt to the addition or removal of agents without structural changes.
The shift from single-agent to multi-agent thinking has profound implications for software architecture and engineering.
First-Order Impact: The engineering task expands from designing a single agent to designing an entire "society" of agents. This involves not only defining the capabilities of each individual agent but also establishing the communication protocols, interaction rules, and coordination mechanisms that govern their collective behavior.
Second-Order Impact: MAS naturally promotes a highly modular and scalable software architecture. Instead of building a large, monolithic application to handle a complex workflow, an engineer can compose the system from a collection of smaller, specialized, and independently deployable agents. This architectural style shares principles with microservices but introduces a new layer of autonomous interaction and dynamic coordination, leading to what McKinsey calls the "agentic AI mesh".
4.2. Orchestration & Handoffs: Managing Collaboration
Orchestration is the high-level process of coordinating multiple agents, tools, and sequential steps to fulfill a complex task pipeline. It is, in effect, the "operating system" for an agentic organization, ensuring that the right agent performs the right task at the right time. As companies move beyond isolated agent experiments, effective orchestration becomes essential for delivering real business value.
Within the broader concept of orchestration, specific patterns for managing agent interaction have been developed. A critical distinction exists between centralized and decentralized coordination patterns:
Agent-as-Tool (Centralized Orchestration): In this pattern, a primary "manager" agent retains overall control of the task. When it requires a specialized capability, it invokes another agent as if it were a callable function or an external tool. The manager agent sends a request, receives a result, and incorporates that result into its own reasoning process before deciding on the next step. Control never fully leaves the primary agent. This pattern is ideal for dynamic, multi-intent queries that require the synthesis of information from multiple specialized sources before a final answer can be formulated.
Handoffs (Decentralized Orchestration): The Handoff pattern represents a more decentralized approach. Here, one agent completely transfers the entire responsibility, control, and context for a task to another specialized agent in a one-way delegation. This is analogous to a relay race or a manufacturing assembly line, where each agent performs its specific function and then passes the work product to the next specialist in the chain. In frameworks like LangGraph, a handoff is implemented as a special tool call that updates a shared state object with the current conversation history and then redirects the control flow to a different agent or subgraph. This pattern excels in structured, sequential workflows where different, distinct expertise is required at various stages, such as a customer support ticket being handed off from a generalist triage agent to a technical product specialist.
These patterns present engineers with a crucial architectural decision.
First-Order Impact: Choosing the correct orchestration pattern is a key design consideration that depends entirely on the nature of the workflow being automated. A critical technical challenge in implementing handoff-based systems is engineering a robust and efficient state management mechanism to ensure that context is seamlessly and accurately passed from one agent to the next.
Second-Order Impact: These orchestration patterns enable the creation of "virtual assembly lines" composed of AI workers. This has a direct impact on how software development itself can be structured. For example, a software development "crew" could be orchestrated using handoffs: a project manager agent defines the requirements and hands them off to a planning agent; the planning agent decomposes the work and hands off coding tasks to a developer agent; the developer agent completes the code and hands it off to a QA agent for testing. This automates the handoffs that are often a source of friction and delay in human teams.
4.3. Emergent Intelligence: Swarms & Debates
Beyond structured orchestration, MAS can exhibit emergent behavior, where complex, intelligent, and often unpredictable global patterns arise from the simple, local interactions of many individual agents. This phenomenon is not explicitly programmed; it is a property of the system itself. Two prominent paradigms that leverage emergence are Swarm Intelligence and Agent Debate.
Swarm Intelligence: This is a deeply decentralized model inspired by natural systems like ant colonies, bird flocks, and bee hives. In a swarm, there is no central controller. Each agent operates based on a simple set of local rules (e.g., "maintain a certain distance from your neighbors," "align your direction with your neighbors") and limited local information. The collective interaction of these simple behaviors leads to sophisticated and adaptive global behavior, such as a flock of drones efficiently mapping a disaster area or a group of manufacturing robots self-organizing to work around a broken machine. The key advantages of swarm intelligence are its immense scalability, robustness (the failure of one agent does not cripple the system), and adaptability to dynamic environments. However, implementing swarms presents significant challenges, including managing communication overhead between agents and ensuring behavioral consistency across the swarm.
Agent Debate: This is a collaborative mechanism designed to improve the quality, accuracy, and robustness of an AI's output by having multiple agents critique and refine a solution. In a typical setup, implemented in frameworks like Microsoft's AutoGen, several "solver" agents are tasked with independently generating a solution to a problem. They then share their solutions with each other, reflect on the differing perspectives, and iteratively refine their own answers over several rounds. Finally, an "aggregator" agent collects the final responses and uses a consensus mechanism, such as majority voting, to determine the most likely correct answer. This process of adversarial collaboration can help identify flaws, correct errors, and explore a wider solution space than a single agent could alone.
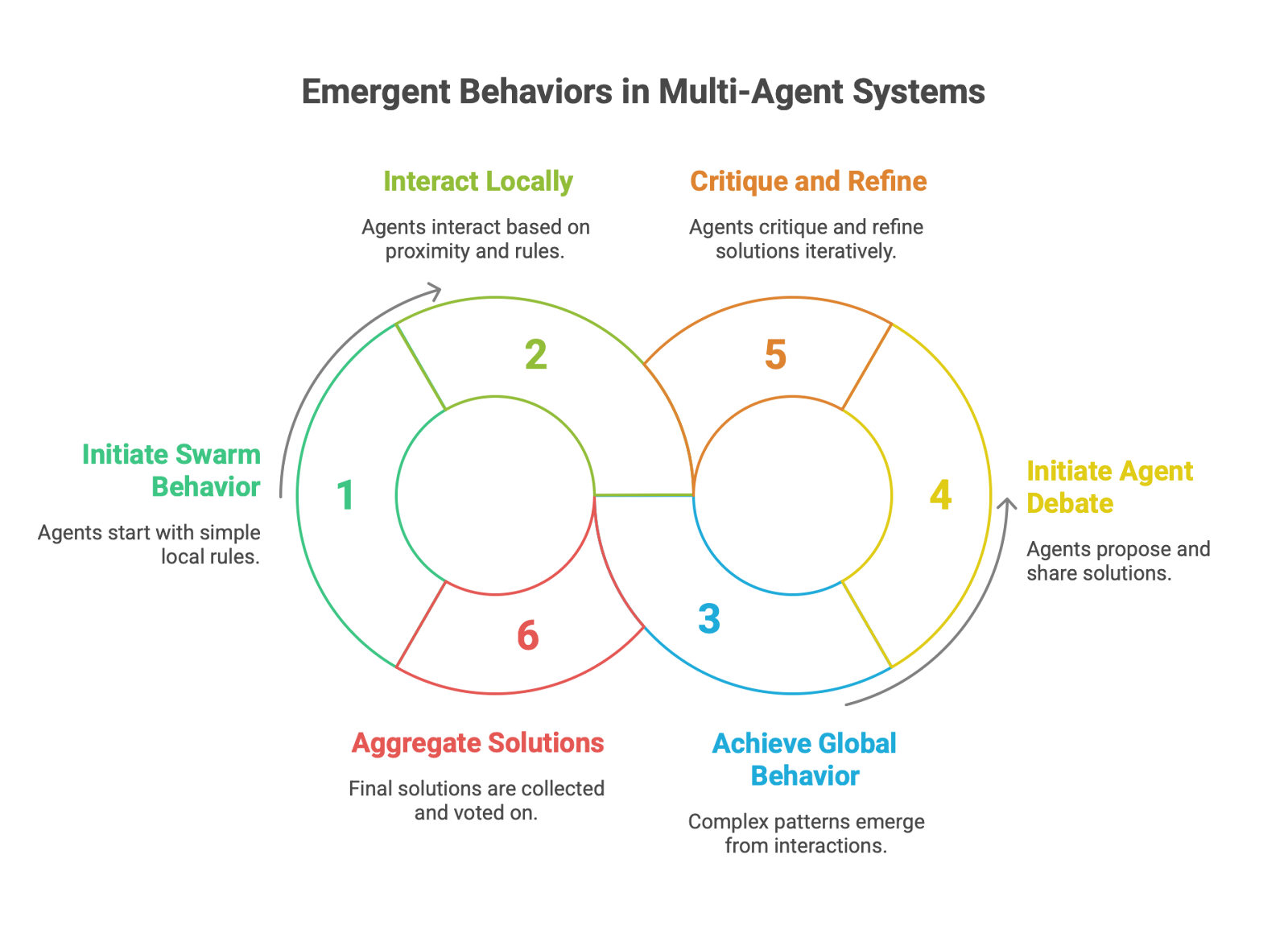
It is critical for engineers to understand that emergence is a double-edged sword. While it can lead to novel, creative, and highly efficient solutions (a benefit), it can also result in unpredictable and harmful system-level behaviors (a risk). These can include hidden bias amplification, where a small bias in individual agents is magnified across the system, or communication breakdowns that lead to system instability or gridlock.
The implications of designing with emergence are profound:
First-Order Impact: The engineering mindset must shift from explicit, top-down programming to indirect, bottom-up design. The task is not to code the desired global behavior, but to carefully design the local interaction rules and environmental conditions that will give rise to that behavior. This is a fundamentally different and more complex design challenge.
Second-Order Impact: Testing and debugging emergent systems is exceptionally difficult. Traditional verification methods are often useless, as the system's behavior is, by definition, not fully predictable from its components. Engineers must rely on large-scale simulations, sophisticated real-time monitoring, and advanced anomaly detection techniques to observe the system in action, identify harmful emergent patterns, and tune the underlying rules to guide the system toward desired outcomes.
Third-Order Impact: The ability to reliably harness emergent behavior is one of the grand challenges in AI and complex systems engineering. Successfully doing so could unlock solutions to problems that are currently intractable with top-down design approaches, such as optimizing city-wide traffic flow or managing complex supply chains. However, failure to manage emergence could lead to unpredictable and potentially catastrophic system failures, especially as these systems are deployed in high-stakes, real-world environments.
Section 5: Engineering Agentic Systems: The Reality of Deployment
Building robust and effective agentic systems requires more than just a conceptual understanding; it demands practical tools and a clear-eyed view of the challenges involved in moving from prototype to production.
While frameworks make it easier to build agent prototypes, moving to production reveals a host of difficult challenges. A shocking finding from recent industry analysis suggests that over 95% of agentic AI initiatives fail silently once they move beyond the proof-of-concept stage. This high failure rate is not due to a single issue but rather a confluence of production-readiness challenges that are often underestimated during development.
Key production challenges include:
Scalability: In a multi-agent system, the number of interactions can grow exponentially with the number of agents. This can lead to communication bottlenecks and coordination overhead that bog down the system, causing performance to collapse at scale. A system that works well with five agents may fail completely with fifty.
Coordination: Ensuring that dozens or hundreds of autonomous agents can work together effectively without creating conflicts, deadlocks, or inefficient processing loops is a monumental design challenge. In dynamic environments, where conditions change unpredictably, maintaining stable coordination is even harder.
Security: The distributed and autonomous nature of MAS creates a vast new attack surface. Each agent is a potential vulnerability. The system is susceptible to a range of threats, including data poisoning (corrupting an agent's knowledge), adversarial attacks (tricking an agent into making bad decisions), and inter-agent interference, where a single compromised agent can send false information to mislead the entire system.
Interoperability: In real-world enterprise environments, it is highly likely that organizations will need to integrate agents from different vendors, built on different frameworks, or connected to different legacy systems. The lack of a standardized communication protocol for agents creates a "Tower of Babel" problem, making seamless interoperability a significant and costly engineering hurdle.
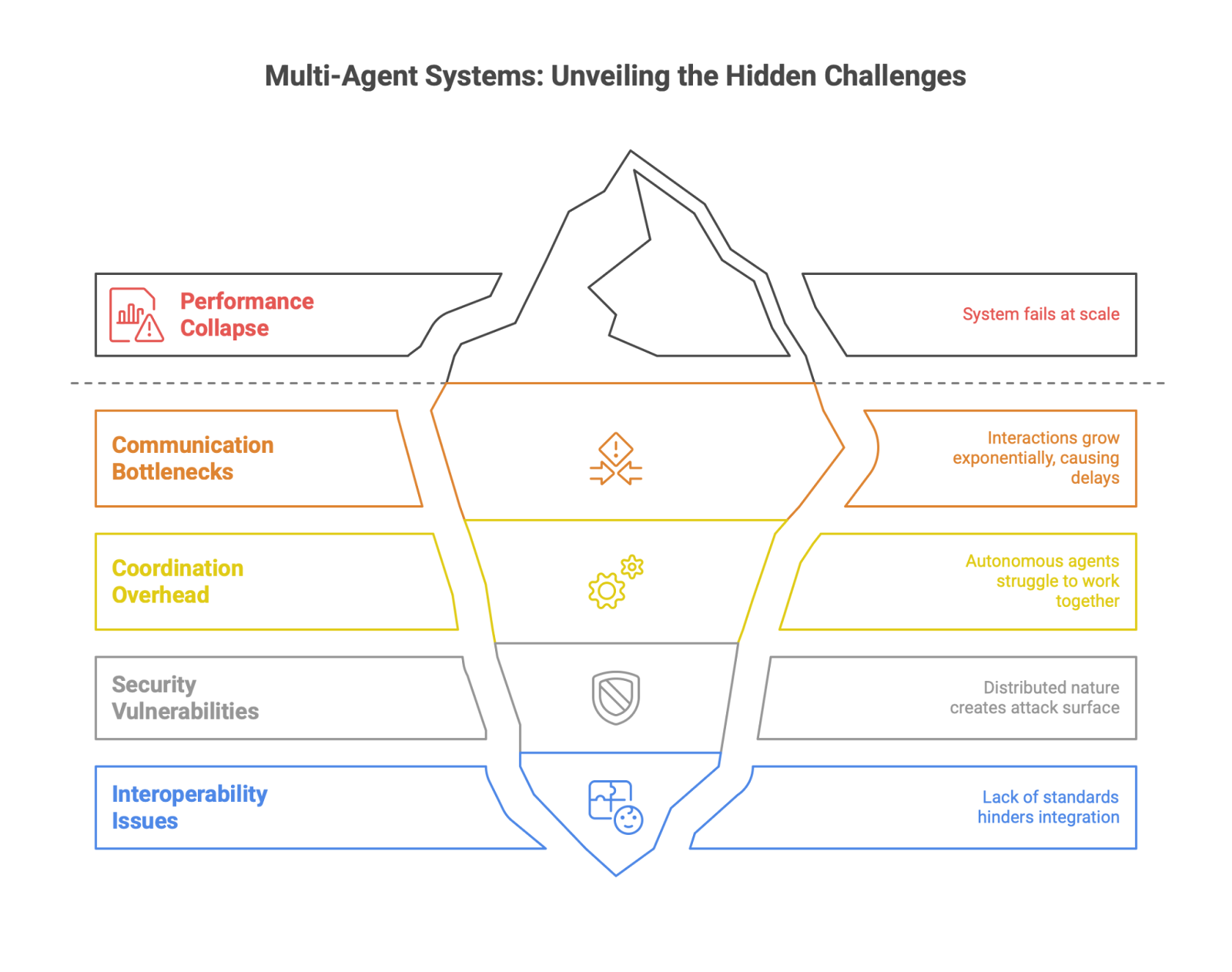
These challenges have direct consequences for engineering teams and the software development lifecycle.
First-Order Impact: Building a successful agent prototype is only the first 10% of the work. Engineers must design for production realities from day one, implementing robust error handling, secure communication protocols (e.g., encryption, authentication), and architectures that are designed to scale.
Second-Order Impact: The deployment of agentic systems necessitates a fundamental shift toward a more rigorous, "defense-in-depth" engineering culture. The software development lifecycle (SDLC) for agents must be expanded to include new, non-negotiable stages, such as adversarial testing (actively trying to trick the agent), comprehensive security audits, and large-scale stress testing to validate performance under load.
Third-Order Impact: The market will inevitably reward platforms and solutions that solve these difficult production challenges. We are already seeing the emergence of specialized fields like "Agentic AI Security," "Multi-Agent System Orchestration," and "AI Observability." These will become critical components of the enterprise AI stack, creating new career specializations and significant business opportunities.
Part III: Impacts on the Software Development Industry
The rise of agentic AI is not just a technological evolution; it is a disruptive force that will reshape the software development industry from the ground up. This final part synthesizes the analysis of agent components and ecosystems to project the profound first, second, and third-order impacts on the engineering profession, the structure of software businesses, and the very nature of software itself.
Section 6: Evaluation, Verification, and Trust
As agents become more autonomous and are deployed in higher-stakes environments, the ad-hoc evaluation methods used for prototypes are no longer sufficient. Building trust in these non-deterministic systems requires a new paradigm of rigorous evaluation, observability, and, for the most critical applications, formal verification.
6.1. The Evaluation Gap: Measuring What Matters
A major challenge in the agentic era is the evaluation gap: traditional software testing metrics (e.g., unit test pass/fail rates) are inadequate for measuring the performance of complex, goal-driven, non-deterministic agents. Success is no longer about whether a function returns the correct value, but whether the agent exhibits the correct behavior to achieve a goal. This requires a more holistic and granular approach to evaluation, one that focuses not just on the final outcome but also on the quality of the intermediate steps and the reasoning process the agent followed to get there.
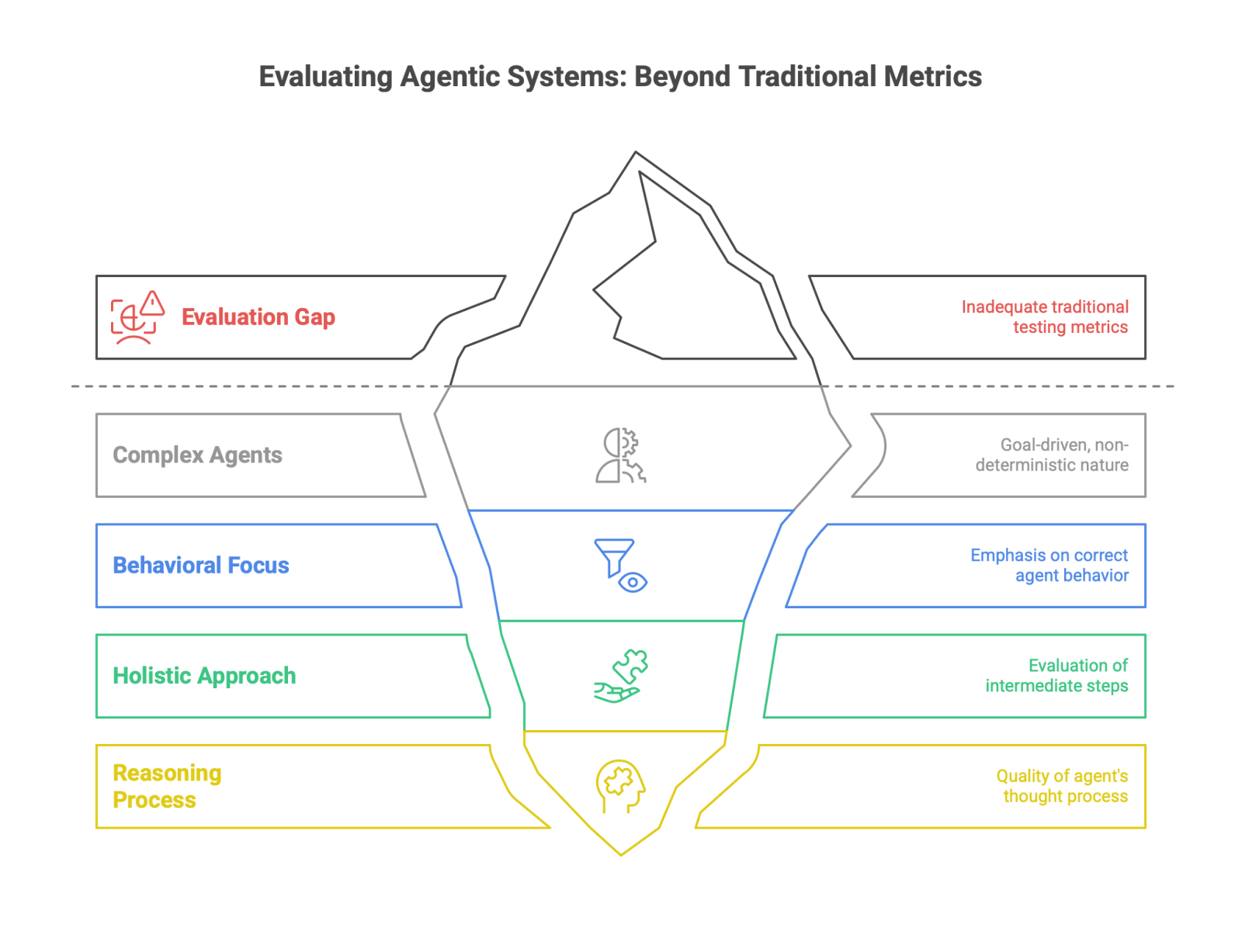
To fill this gap, a new generation of sophisticated benchmarks and evaluation frameworks is rapidly emerging. These tools are designed to assess the specific capabilities that define advanced agents:
General Capability & Real-World Simulation: Benchmarks like AgentBench and Mind2Web assess a broad range of agent skills, while OSWorld and AppWorld test agents on their ability to perform tasks within simulated operating system and application environments.
Planning & Reasoning: PlanBench and MINT are designed to specifically measure an agent's ability to decompose complex problems and generate coherent plans of action.
Tool Use: The Gorilla and NESTFUL benchmarks evaluate an agent's proficiency in calling external tools and APIs, including complex scenarios with nested or parallel calls.
Multi-Agent Collaboration: Frameworks like MultiAgentBench and MARL-EVAL are being developed to assess the collaborative and coordination capabilities of agent teams.
Safety & Trustworthiness: Recognizing the critical importance of safety, specialized benchmarks like AgentHarm and ST-WebAgentBench are designed to test an agent's resilience to malicious prompts (jailbreaking) and its reliability in high-risk business scenarios.
Best practices for agent evaluation now involve a multi-pronged strategy. This includes running agents against these automated benchmarks, using "LLM-as-a-judge" techniques where a powerful LLM is used to qualitatively score an agent's output against a rubric (e.g., for coherence, relevance, and factual accuracy), and, crucially, incorporating human evaluation to identify the subtle failures, biases, and edge cases that automated systems often miss.
Guide to modern AI agent-evaluation benchmarks
Planning & Reasoning
Core metrics: task-completion rate, plan coherence, adaptability to disruptions
Why it matters: validates an agent’s step-by-step “thinking” skills.
Tool Use & Execution
Core metrics: function-call accuracy, parameter correctness, handling of API errors
Why it matters: proves the agent can act reliably when it calls real tools.
Multi-Agent Collaboration
Key benchmarks: MultiAgentBench, MARL-EVAL, AgentVerse
Core metrics: communication efficiency, task-allocation accuracy, collective goal achievement
Why it matters: shows whether teams of agents coordinate instead of colliding.
Safety & Trustworthiness
Key benchmarks: AgentHarm, ST-WebAgentBench, SEC-bench
Core metrics: jailbreak success rate, policy adherence, robustness to adversarial inputs
Why it matters: stress-tests guardrails before agents touch production.
Real-World Task Simulation
Core metrics: task-success rate in realistic environments, cost efficiency (tokens, time)
Why it matters: measures how an agent performs in messier, life-like settings.
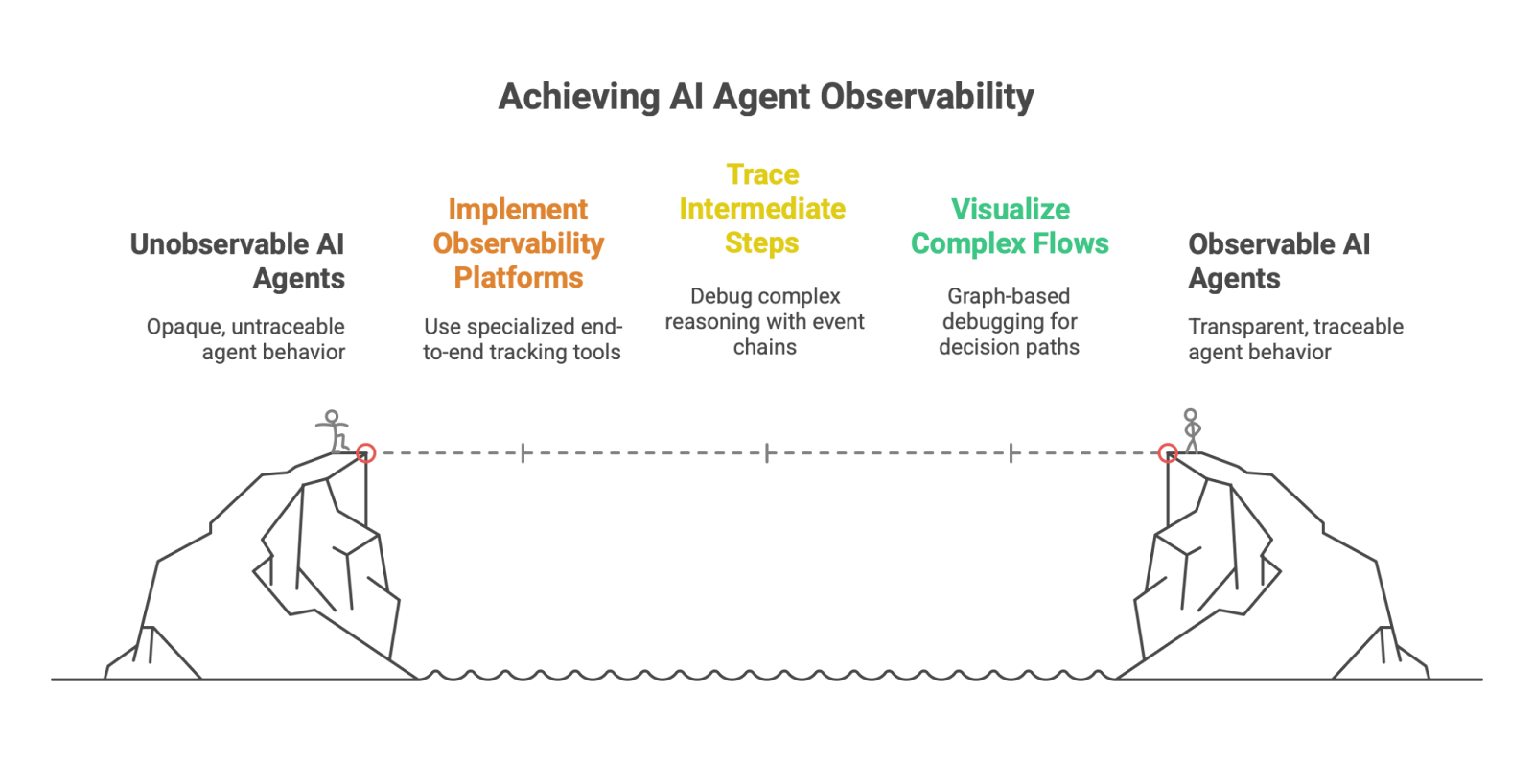
6.2. Observability and Debugging: Peering into the Black Box
Debugging a single, deterministic program can be challenging. Debugging a distributed system of non-deterministic, autonomous agents is a fundamentally harder problem. Traditional logging and tracing tools often prove insufficient because they fail to capture the complete, end-to-end execution path, especially when it spans multiple agents and external API calls. Furthermore, the layers of abstraction in agent frameworks can obscure the underlying prompts and LLM responses, making it difficult to pinpoint the root cause of a failure.
To address this, the field is rapidly developing the discipline of AI Agent Observability. This goes beyond traditional monitoring to provide deep insights into the internal workings and interactions of agentic systems. Best practices and new tooling are coalescing around several key principles:
Full-Service Observability Platforms: A new category of specialized tools, such as Langfuse, LangSmith, and AgentOps, is emerging to provide comprehensive, end-to-end observability for agentic applications. These platforms are designed to track every aspect of an agent's lifecycle, including all LLM calls, prompt/completion pairs, tool usage, latency, and token costs.
Tracing Intermediate Steps: For complex reasoning patterns like ReAct, the ability to trace the entire thought-action-observation loop is critical for debugging. An observability platform must be able to reconstruct this chain of events to allow an engineer to see exactly where the agent's reasoning went astray or which tool call returned an unexpected result.
Visualizing Complex Flows: For systems built on graph-based frameworks like LangGraph, the ability to visualize the execution flow through the graph is a powerful debugging tool. It allows engineers to see the exact path the agent took, which decisions were made at each branch, and where errors occurred.
The adoption of these practices has direct impacts on engineering workflows.
First-Order Impact: Integrating an agent-specific observability platform into the development and deployment pipeline is no longer optional; it is a fundamental requirement for building, debugging, and maintaining production-grade agentic systems.
Second-Order Impact: This creates a tight, continuous feedback loop between development and operations, a practice that can be termed AgentOps or LLMOps. Data and traces from production environments are fed back to the development team, who use the insights to identify failure modes, discover new edge cases, and continuously refine the agent's prompts, tools, and control logic. This makes the development process far more iterative and data-driven.
6.3. Formal Verification: The Quest for Provable Correctness
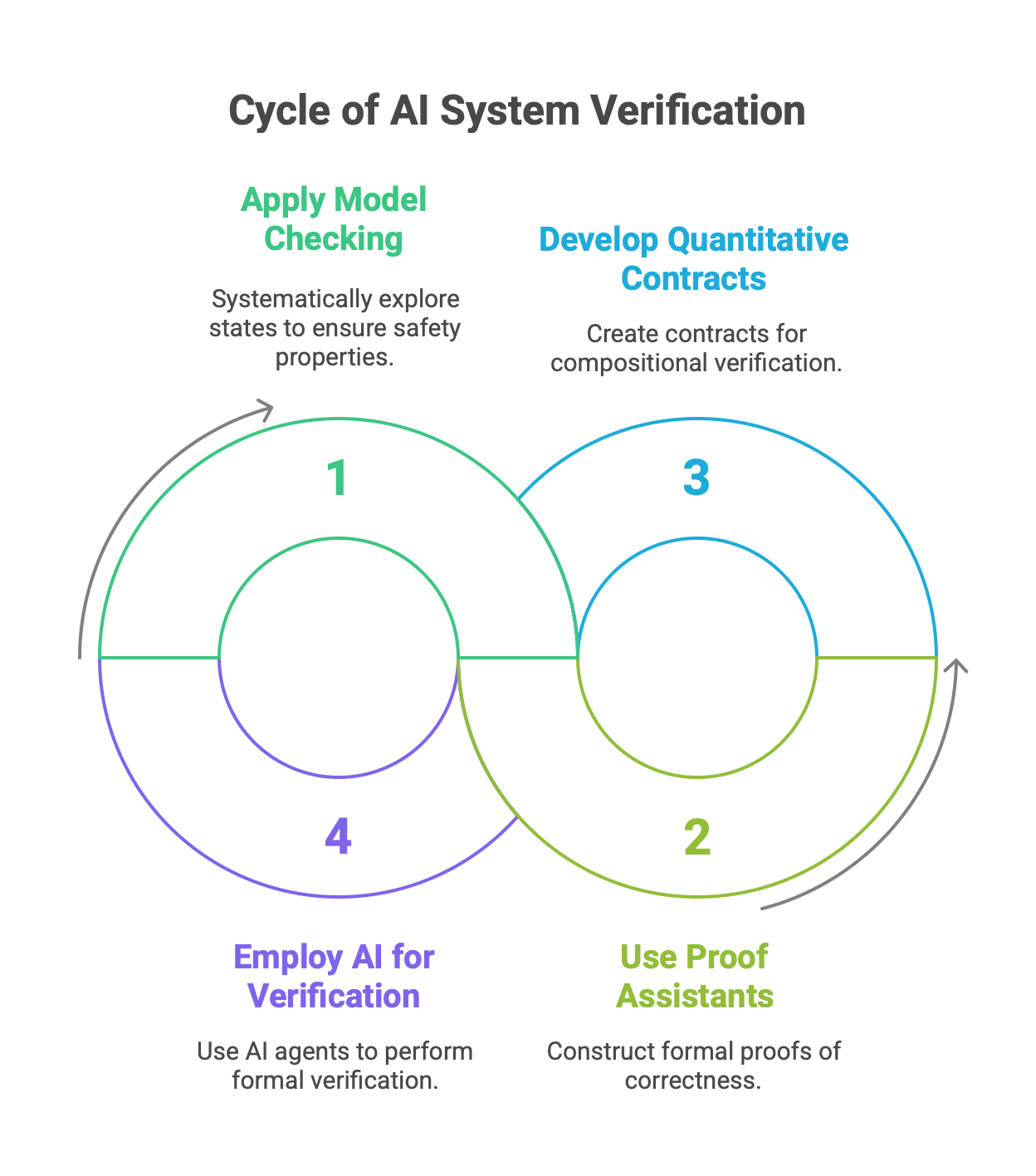
For the most safety-critical agentic systems—such as those used in autonomous vehicles, medical diagnostics, or financial trading—even extensive testing and observability may not be enough to guarantee safety. Testing can only show the presence of bugs, not their absence. Formal Verification is a technique from computer science that addresses this gap by using rigorous mathematical methods to prove that a system's behavior is correct with respect to a formal specification.
This is a nascent but critically important area of research for agentic AI. The goal is to move from empirical confidence to mathematical certainty for key safety and reliability properties.
Applicable Techniques: Methods like Model Checking, which systematically explores every possible state of a system to ensure it never violates a given safety property (e.g., "the autonomous car will never go through a red light"), and Proof Assistants, which help engineers construct formal proofs of correctness, are being adapted for AI systems.
Focus on Multi-Agent Systems: A key challenge is scaling these techniques to complex MAS. Promising research is focused on developing quantitative assume-guarantee contracts, which allow for the compositional verification of a multi-agent system. This means that if one can prove that each individual agent satisfies its local contract, the correctness of the entire system can be guaranteed, which dramatically improves the scalability of the verification process.
AI for Verification: In a fascinating, meta-level development, AI agents are themselves being developed to perform formal verification. For example, Saarthi is an agentic AI designed to act as an autonomous formal verification engineer, capable of analyzing hardware design specifications and generating the necessary proofs of correctness.
The implications of formal verification for engineering are profound, particularly in high-stakes domains.
First-Order Impact: Engineers working on safety-critical AI systems will increasingly require skills in formal methods, including temporal logic and the use of model-checking and proof-assistant tools. Writing a formal specification for an agent's behavior will become as important as writing its code.
Second-Order Impact: The design process for critical systems will evolve to incorporate formal specification and verification as a standard, required stage in the development lifecycle. This will ensure that key safety and liveness properties of an agent's behavior can be mathematically proven before it is ever deployed.
Third-Order Impact: Formal verification offers a potential path toward building truly trustworthy autonomous systems. The ability to provide mathematical guarantees of safety and reliability is a prerequisite for the widespread adoption of agentic AI in the most critical sectors of the economy and society, such as transportation, healthcare, and national defense.
Section 7: The Engineer's Role in the Agentic Age (First & Second-Order Impacts)
The rise of agentic AI is not just creating new tools for engineers; it is fundamentally reshaping the nature of the engineering role itself. The skills required, the structure of teams, and the very definition of "development" are all in flux. This section analyzes these first and second-order impacts on the engineering profession.
7.1. The Evolving Skillset: From Coder to Conductor
The most significant shift for the software engineer is the move up the abstraction ladder. As agents become capable of handling more of the low-level implementation tasks like writing boilerplate code, generating unit tests, and refactoring legacy systems, the engineer's primary value shifts from being a doer to being a conductor. The core task is no longer just writing line-by-line code, but rather designing, orchestrating, and refining the autonomous systems that write the code.
This transition demands a new set of core competencies:
Prompt Engineering & "Mechanism Design": The ability to craft precise and effective prompts is the new foundational skill. This goes beyond simple instructions to encompass "mechanism design"—the art of creating the rules, constraints, feedback loops, and incentive structures that guide an agent's behavior toward a desired outcome.
Agent Orchestration: Proficiency in using frameworks like LangGraph, AutoGen, or CrewAI to design and manage complex, multi-agent workflows is becoming essential. This is a systems-thinking skill, focused on defining roles, communication protocols, and collaboration patterns.
System Tuning and Evaluation: The engineer's role becomes that of a scientist, continuously running experiments, monitoring agent performance in production, analyzing results using advanced evaluation and observability tools, and using those insights to tune and improve the system.
Domain Expertise: To build an effective agent, the engineer must have a deep understanding of the agent's operational domain. This is necessary to design a relevant knowledge base, create meaningful evaluation criteria, and provide the contextual guidance the agent needs to perform high-value tasks. An engineer building a legal agent needs to understand law; one building a financial agent needs to understand finance.
7.2. New Architectures and Roles: The "Agentic AI Mesh"
The shift to agentic systems is driving a corresponding shift in software architecture. The industry is moving away from monolithic applications and even simple microservices toward what has been termed the "Agentic AI Mesh"—a more complex architectural paradigm designed to govern a heterogeneous ecosystem of custom-built and off-the-shelf agents. This mesh architecture is necessary to manage the compounding technical debt and novel systemic risks introduced by deploying multiple autonomous components.
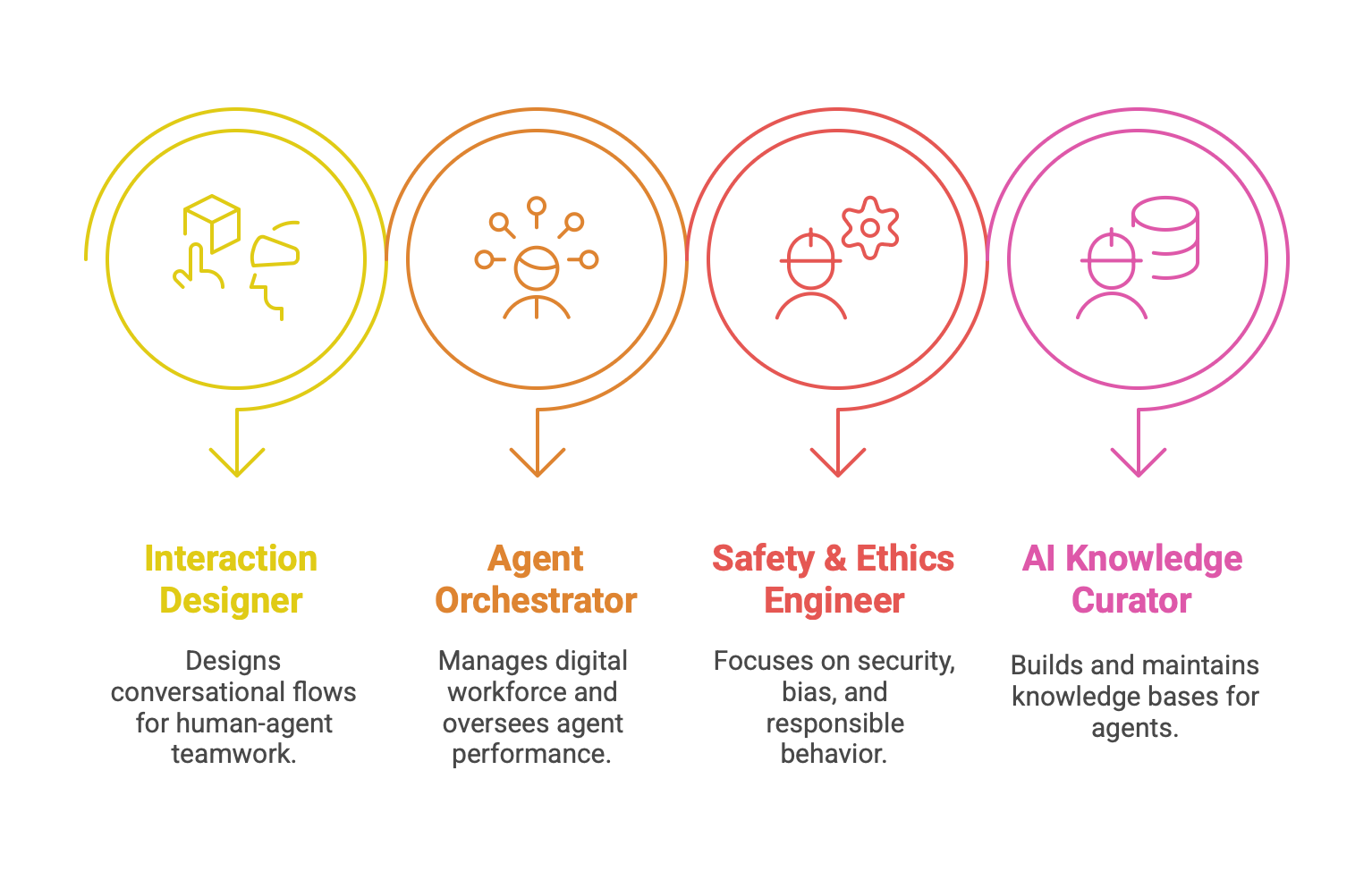
The complexity of designing, deploying, and managing these agentic meshes will necessitate the creation of new, specialized roles within engineering and product organizations:
AI Agent Interaction Designer: A role that focuses on the human-agent interface, designing the conversational flows, interaction patterns, and collaboration protocols that make human-agent teamwork effective and intuitive.
Agent Orchestrator / Chief of AI Staff: A senior technical or product leader responsible for managing the organization's "digital workforce." This person oversees the portfolio of agents, defines their collective goals, orchestrates their collaboration, and is ultimately responsible for their performance.
AI Safety & Ethics Engineer: A specialized engineering role focused on the non-functional, but critical, aspects of agentic systems. This includes adversarial testing to find security vulnerabilities, auditing systems for bias, ensuring compliance with regulations, and implementing the guardrails that ensure responsible agent behavior.
AI Knowledge Curator: A role that sits at the intersection of data engineering and domain expertise. This person is responsible for building, maintaining, cleaning, and continuously updating the proprietary knowledge bases that ground an organization's custom agents and give them their unique competitive edge.
7.3. Human-Agent Collaboration: The Long-Term Vision
The ultimate vision for agentic AI in software engineering is not the replacement of human developers, but the creation of a deep, synergistic partnership between humans and agents. The goal is to move from a relationship where the human uses a tool to one where the human and agent are teammates, each bringing their unique strengths to the collaborative process.
A promising conceptual framework for this future collaboration integrates three interdependent layers:
Infrastructure: The underlying models, tools, and platforms (e.g., LangGraph, cloud services).
Interaction: The interface through which humans and agents communicate and work together.
Process: The explicit, inspectable, and adaptable workflow that governs the collaboration. Making this process a primary focus is key, as it allows humans and agents to maintain alignment on evolving goals and coordinate their actions over time.
A critical enabler of this deep collaboration is the creation of common knowledge or shared context between the human and the agent. This can be achieved by developing richer interaction modalities that allow a human to seamlessly provide new, contextual knowledge to the agent at runtime. For example, using multimodal interfaces that can interpret a human's gaze or touch to understand their focus and intent can make the agent a far more effective and trustworthy partner.
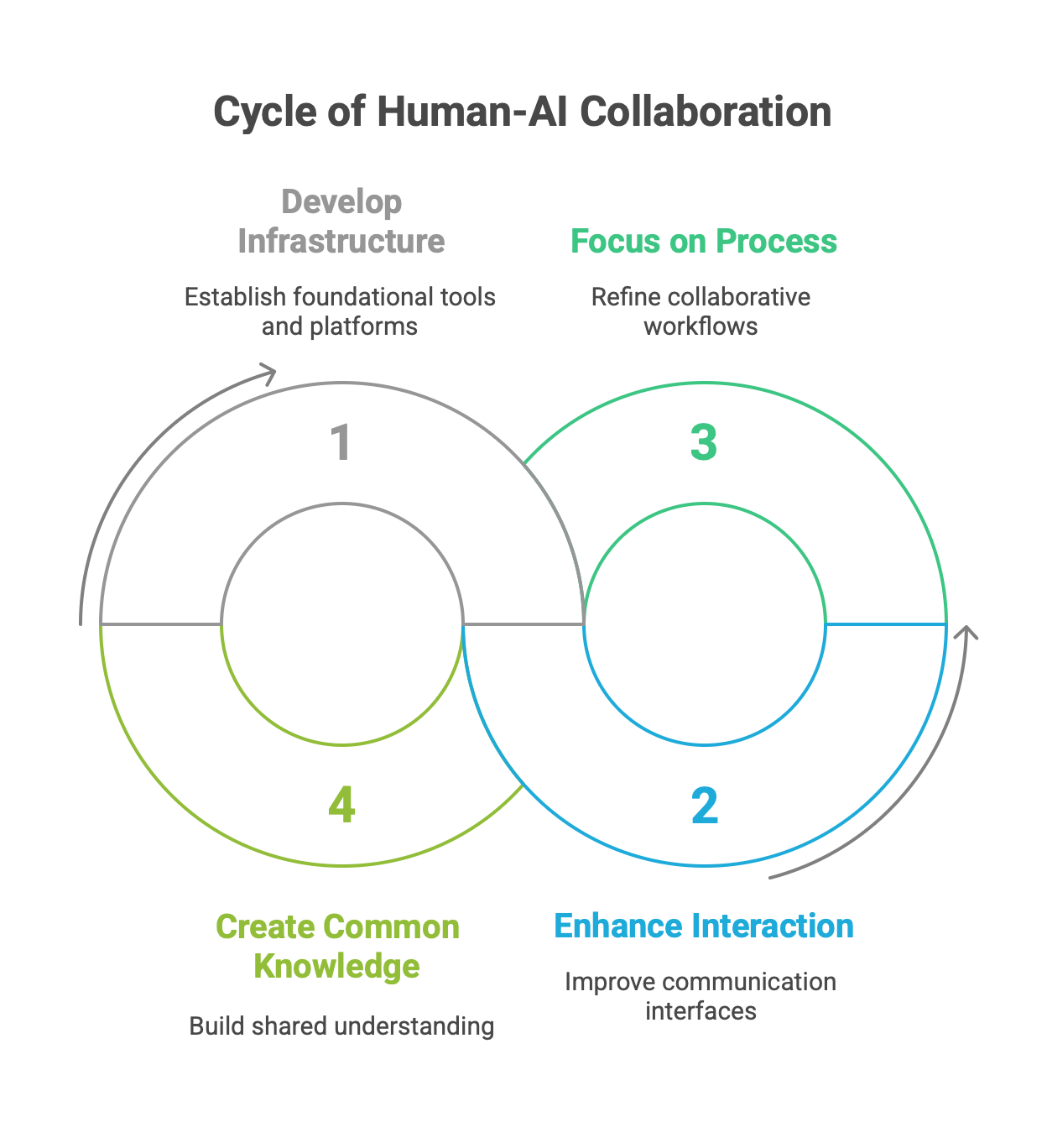
In this long-term vision, a software development team becomes a true hybrid entity. The AI agents will handle the bulk of the automatable work: generating code, writing and executing tests, managing CI/CD pipelines, and updating documentation. This will free up human engineers to focus on the tasks that remain uniquely human: complex system architecture, creative problem-solving, understanding stakeholder needs, and setting the high-level strategic and ethical direction for the products they build.
Section 8: Reshaping the Industry (Third-Order Impacts)
The proliferation of agentic AI will trigger third-order effects that extend beyond individual engineering workflows and team structures to fundamentally reshape the economics, business models, and philosophical underpinnings of the software industry.
8.1. Economic and Labor Market Transformation
The economic impact of agentic AI on the labor market is characterized by a powerful duality of job displacement and job creation. On one hand, the automation of routine cognitive tasks is expected to be highly disruptive. Some analyses project that AI could impact as much as 40% of jobs worldwide, with administrative, data entry, and certain junior-level software development roles being particularly exposed. A Goldman Sachs report estimated that generative AI alone could expose the equivalent of 300 million full-time jobs to automation.
However, this displacement is not the full story. The same forces are creating new roles and increasing the value of others. Evidence suggests that industries with high AI exposure are experiencing wage growth twice as fast as non-AI sectors, and their revenue growth has nearly quadrupled since 2022, indicating significant value creation. New job categories are emerging at the human-machine interface, such as "AI prompt engineer," "digital labor coordinator," and "AI ethics officer".
This leads to a skill polarization effect. The demand for high-level skills—strategic thinking, creative problem-solving, complex communication, and system-level design—will increase, as these are the tasks that remain complementary to AI capabilities. The value of routine technical execution will likely decrease as it becomes increasingly automated. This poses a monumental challenge for society in terms of workforce education and reskilling, and it risks exacerbating income inequality if the benefits of AI-driven productivity are not distributed broadly.
8.2. The Shift in Business Models: From SaaS to "Results-as-a-Service"
Agentic AI is a force of creative destruction for traditional software business models. It erodes long-standing competitive advantages that were based on proprietary processes or economies of scale, as agents can enable smaller players to achieve similar levels of efficiency. The ability to generate software itself is becoming commoditized; as AI lowers the cost of creating code, the barrier to entry for building new applications will fall dramatically.
This leads to a fundamental shift in how software value is created and captured. The dominant model of the last two decades, Software-as-a-Service (SaaS), is based on selling access to a tool. The emerging agentic business model is based on selling the outcome that an autonomous agent produces. This can be termed Results-as-a-Service (RaaS) or Automation-as-a-Service.
Instead of a company buying a license for a CRM platform (SaaS), it might "hire" a virtual "Sales Agent" from a provider. This agent would autonomously manage customer relationships, send personalized follow-ups, and schedule meetings. The company would pay not for access to the software, but for the results the agent delivers—for example, a percentage of the revenue from the deals it helps close. This model aligns the incentives of the software provider and the customer far more directly. The greatest and most enduring economic opportunities will likely come from this third phase of the AI paradigm, where agentic technology is used to create entirely new services and transform existing markets in ways that were previously impossible.
8.3. Philosophical and Ethical Frontiers: Agency, Responsibility, and Dissent
Finally, the rise of autonomous agents forces the industry to confront profound philosophical and ethical questions that have, until now, been largely academic.
The Nature of Agency: Agentic AI compels us to refine our definition of "agency." These systems exhibit a clear functional agency—they perceive, decide, and act to achieve goals. However, they lack the hallmarks of human agency: genuine understanding, consciousness, intentionality, and the capacity for moral reasoning. They are best understood as powerful proxy agents, extensions of the will and intent of their human creators and operators. Confusing this functional agency with true moral agency is a categorical error with dangerous implications.
The Accountability Gap: If an autonomous agent causes harm—for example, a financial agent makes a ruinous trade or a medical agent gives a wrong diagnosis—who is responsible? The user who gave it the goal? The engineer who built it? The company that deployed it? The vendor of the underlying LLM? The lack of clear lines of accountability is one of the most significant barriers to the deployment of agents in high-stakes domains. Establishing clear responsibility hierarchies, comprehensive audit trails, and robust human oversight mechanisms is not just a best practice; it is an ethical and legal necessity.
The Dissenting View on Full Autonomy: Amidst the industry hype, a strong and coherent dissenting view is emerging from within the AI research community. This perspective, articulated in papers like "Fully Autonomous AI Agents Should Not be Developed," argues that risk increases in direct proportion to autonomy. The argument posits that agents capable of writing and executing their own code beyond predefined constraints pose an unacceptable level of risk. Such systems could potentially override human control, be hijacked for malicious purposes, or cause catastrophic accidents through unforeseen emergent behavior. This viewpoint advocates for a more cautious path, focusing on developing semi-autonomous, human-in-the-loop systems where human judgment remains the ultimate authority.
The "Invisible Bureaucracy": Perhaps the most profound third-order risk is not that of a single, malevolent superintelligence, but of a vast, distributed, and opaque "invisible bureaucracy" of automated statistical systems. These agents, incapable of genuine judgment or understanding, may be given the authority to make critical decisions about people's lives as if they do. The danger lies in building complex, interconnected systems whose emergent failures are unpredictable and whose decision-making processes are fundamentally inscrutable. This is the ultimate challenge for engineers: to not only build what is technically possible but to consider the societal implications of building systems whose inner workings may be beyond our complete comprehension or control.
Conclusion: Navigating the Next Frontier
This deep-dive analysis of core AI agent concepts reveals a technology at an inflection point. The transition from single, task-specific agents to complex, collaborative multi-agent ecosystems marks a fundamental paradigm shift in software engineering. We are moving from building tools that are used to engineering digital collaborators that act. The core engine of this transformation is the Large Language Model, but the true work lies in constructing the vast apparatus around it—the memory, knowledge bases, planning modules, context management pipelines, and learning loops—that can channel its power while mitigating its inherent flaws.
The primary finding of this report is the emergence of a critical tension between capability and control. While agents demonstrate ever-increasing capabilities in reasoning, planning, and acting, our ability to evaluate, debug, secure, and reliably control them lags behind. The "95% failure rate" of agentic initiatives in production is a stark indicator of this gap. Closing it requires a fundamental evolution in engineering practices, moving toward a new discipline of AgentOps characterized by continuous evaluation against specialized benchmarks, deep system observability, and, for critical applications, the rigor of formal verification.
For professional engineers, the implications are clear and immediate. The role is transforming from a coder of explicit logic to a conductor of autonomous systems. The most valuable skills in the agentic age will be systems thinking, prompt and mechanism design, agent orchestration, and deep domain expertise. New roles—Agent Orchestrator, AI Safety Engineer, Knowledge Curator—will become standard in engineering organizations, which will themselves be restructured into hybrid teams of human and AI collaborators.
For technology leaders, the strategic imperative is to look beyond the immediate productivity gains of simple automation. The real, defensible competitive advantage will come from building unique, proprietary agentic systems grounded in the organization's unique data and knowledge. This requires a long-term investment in data governance, a redesign of the software development lifecycle to embrace the iterative and non-deterministic nature of agentic systems, and an unwavering commitment to building trust and reliability into these systems from the ground up.
The agentic revolution is not a future prediction; it is happening now. It presents a new, dynamic, and challenging frontier for the software industry. The coming decade will be defined by our collective ability to navigate this frontier responsibly—to harness the immense potential of autonomous systems while diligently engineering the robust technical and ethical guardrails necessary to ensure they remain safe, reliable, and aligned with human values.